To Auto Scale or not to Auto Scale, that is the question
The challenges of Auto Scaling, from cold start impact, tech debt, and cost realities. Prioritising scaling as code and shared responsibility for optimal performance in cloud efficiency.

If you've read my more recent blog post around Scaling the Sidecar, you'll have picked up on the fact that I actually don't like Auto Scaling our workloads. Today I'm going to dig into a little bit more why that's the case, based on the types of workloads that we run at Auto Trader.
To be clear, I'm not sat here saying that you shouldn't Auto Scale either. Make your own decisions on what's right for your problem space. You could also read this blog from an inverse perspective of "Challenges to tackle if you want to Auto Scale" too.
Cold Starts hurt Latency
I admit this one is our own doing, but we have a lot of workloads that rely on Just in Time compilation (e.g JVM). That means when instances of those services come up, there's a reasonable period (some seconds or minutes) where latencies are higher, because the code is being compiled on the fly. That means Pod Churn negatively impacts our users. There are ways to minimise the impact of this (some more extreme than others), for example:
- Using warmupDurationSeconds on a DestinationRule, to gradually ramp up traffic.
- Using Kubernetes Start-up Probes to send some requests to known hot paths, before the pod becomes Ready.
- If you're a heavy JVM user like us, look at native compilation like graal, however our experience tells us whilst this helps with startup, JIT performs better once fully warmed.
- There are enterprise JVM offerings like Azul prime, which offer effectively a distributed cache for JIT compilation. But they're quite costly i've found (negating the cost savings of Auto Scaling).
- Pivot to languages that are more aligned with Auto Scaling (native compilation and fast startups - golang, rust, etc).
You'll need to do a lot of these anyway to thrive in a highly ephemeral environment such as kubernetes. There are many reasons pods restart (evictions, deployments, etc). We've invested a lot in ensuring our workloads do this but even so, we still prefer to minimise that pod churn during our peak consumer hours when load is at its highest.
Scaling Masks Problems
Performance regressions get introduced all the time, some subtle and compound over time, others are obvious and immediate. Without a doubt the most common response I see to performance problems is "lets scale it". It's quick, it's easy, and it generally works (up to a point).
I however see this as Tech Debt, but even worse it's Tech Debt that you're not actively tracking. That will compound over time and eventually you'll be at a breaking point. It might be service performance, or simply cost of scaling up constantly, but you'll be unpicking potentially years of regressions.
I always encourage scaling after you've understood the performance of your service, not before. More often than not this simple mentality switch results in the issue being resolved without scaling.
Here's a real world example for you. One of our Vehicle Metrics team had deployed an ML API (in Python) and started routing traffic to it. Response times weren't quite where they wanted to be and their initial instinct was to scale. Without any data there was a belief that ML APIs are just inherently CPU intensive so we'd need to scale. I challenged them to show that with Data.
Python is relatively immature here in terms of our runtime debug capability, so getting that data wasn't actually an option for them. This is where the Platform Team fit into our organisation. We worked with them to build a capability to generate flame graphs (with py-spy) from running Python pods. This requires running a privileged debug container, which we exposed behind our developer dashboard:
Upon digging into the flame graphs, it became obvious a significant amount of time was spent doing in-memory sorts. They realised that in their model output, they'd missed an index.
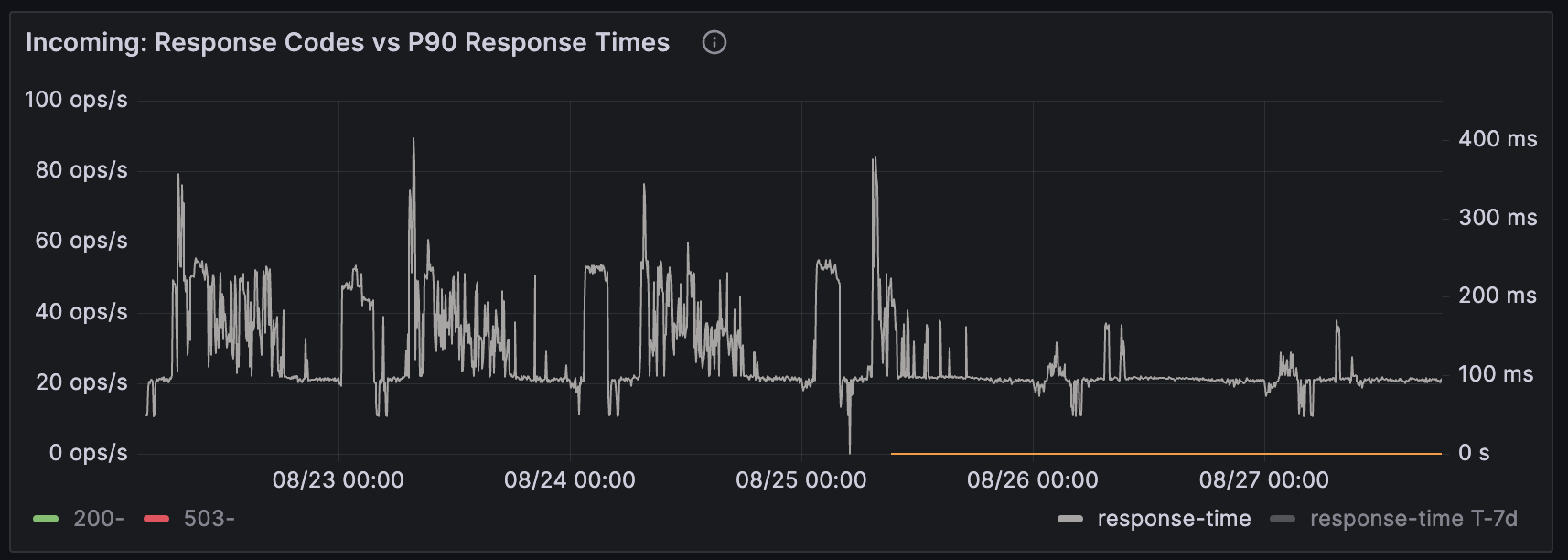
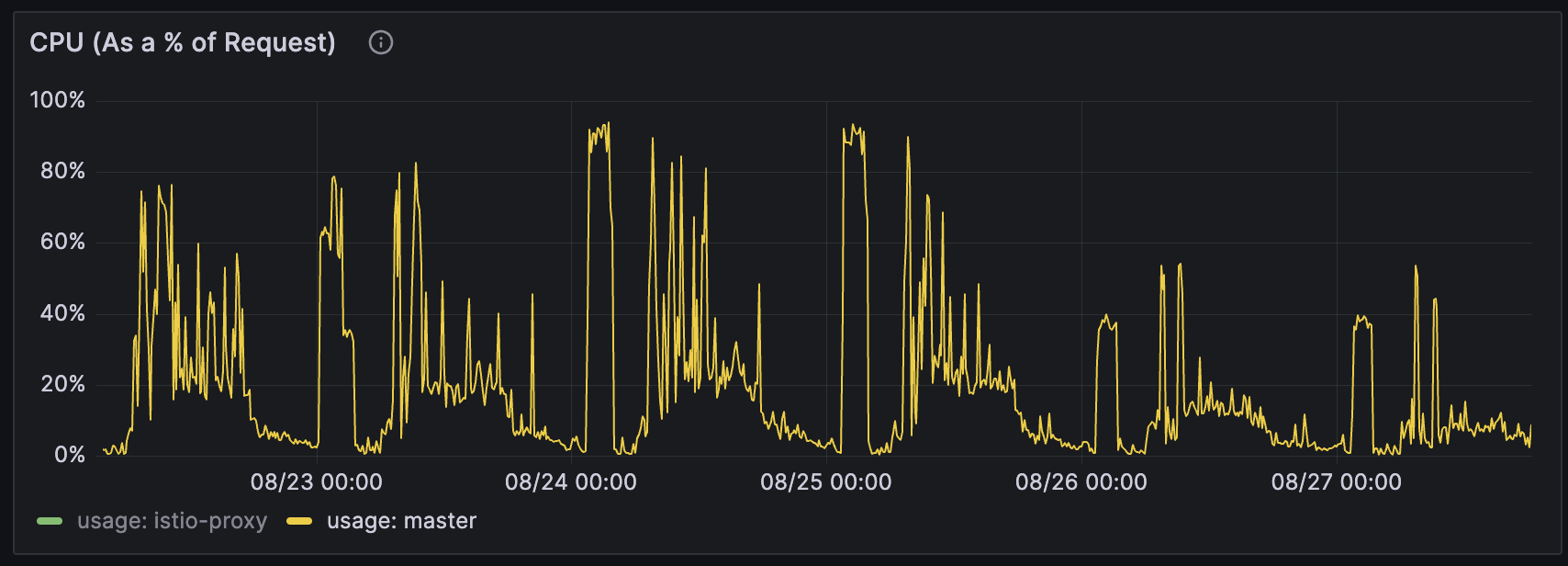
A simple one line fix in their code halved response time, and cpu time. And the problem was solved, without scaling. But on top of that, we'd added a capability to the platform that meant future python application developers could now self serve data that enables them to debug performance problems too. They talked about this in a brown bag session which helps to grow a culture of valuing performance profiling.

So as you can see here for me, scaling something should generally be a conscious decision. Therefore Auto Scaling is automating a decision that I personally don't believe should be automated. Obviously the natural workaround to this would be to set an upper limit on your Auto Scaler but I find this just reinforces a culture of scale first, whereas I prefer to see debug first, scale later.
Because of this, scaling at Auto Trader is done as code, it's committed into the Git repository, goes through CI, runs through any tests, and is deployed to multiple environments before prod. The reason for scaling is cemented in the Git message, and we have automation that shares in slack that the scale happened. That slack message tags all the owners of the service - to highlight the fact it happened, and if needs be trigger a "why" type conversation.
You're at the mercy of Infrastructure Capacity
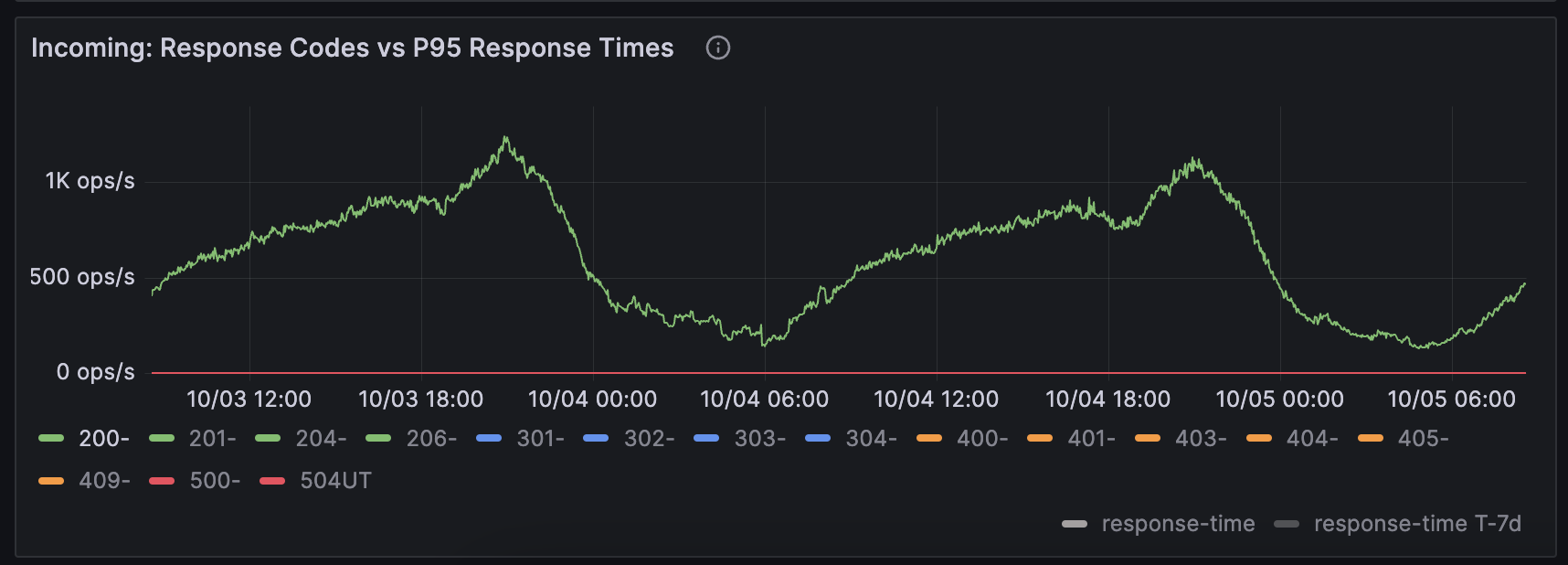
Above shows you the traffic pattern of one of our services. You can see we exhibit a significant seasonality in our traffic patterns, with our peak being in the evening and it being a good 80% lower by 2am. On paper this type of traffic pattern is perfect for auto scaling, it gradually ramps up and down.
In the real world however, if you're auto scaling your Deployment, and your underlying Kubernetes cluster nodes, then your ability to add new nodes to your cluster is dependent on their being availability of the compute machine types you're requesting from your cloud provider. This happens, on Google Cloud Platform at least, more than you'd believe. There's even a blog from a Google TAM here talking about it and how to plan for it.
Whilst experimenting with Auto Scaling we experienced situations where we were unable to scale up to meet customer demand gradually ramping up, despite running in 3 availability zones.
Stock-outs in GCP happen at the Cell level (groups of infra within a zone), then the Zone, then the Region. There's a significant lack of transparency around Capacity and Availability. GCP Support are instructed to provide no timelines for resolution and simply tell you to spin up more capacity in another region for example - as if it's that simple to do.
The ultimate solution proposed by Google is to buy Compute Reservations, the incredible irony here is that you're then pre-buying compute you expect to use to guarantee it's availability. At full price. Immediately negative a any cost savings of auto scaling.
You don't actually save that much money!
I know, I know. At least on Google for us when we add up:
- Committed use discounts - where you commit to buying resources up front
- Sustained use discounts - where you get a discount for using compute constantly
- Committed spend discounts - where you negotiate a discount based on spend over longer term contracts
You can achieve sufficiently high levels of discount on committed use that in our case, we almost entirely offset the savings from a more opex/ephemeral usage pattern.
If you follow the FinOps princples you'll be familiar with the concept that cloud usage is a shared responsibility model. In our organisation, we don't internally charge teams for their cloud usage, we want them to focus on building products. The way the shared responsibility model manifests for us is that the teams right-size their workloads, care about performance, scaling after investigation, not before.
Summary
Auto-scale or not, that's up to you. But nothing in life is free, and auto scaling is not a silver bullet.