Scaling the Sidecar
Scaling Istio Sidecars, and how we consider the relationship of Sidecar resources tightly coupled to the application.

There's a lot of talk at the moment about Istio's new Ambient Mesh. This new approach to deploying your Service Mesh does away with the Sidecar in favour of two new components, ztunnel, a per-node component to handle core L4 networking concerns, and waypoint proxy (if required) to handle L7 concerns.

One of the key drivers for moving away from Sidecars that I keep hearing is that scaling Sidecars is complex. If you only use L4 features, I agree. However - as a heavy user of L7 features, it feels like we'll simply be managing the scale of Waypoint proxies instead of Sidecars. For me, personally and perhaps somewhat selfishly, it feels a sideways (at best) step - rather than forward.
I also don't really feel the pain of managing Sidecar resources, so I'm struggling to relate. That's partly because I've been using Istio since the early days, and have built up tooling, and processes that aid in the process. I realised I'd never really shared much about how we manage this - so here I am.
A bit of context
Context matters, the way you think about monitoring and scaling will depend on how you structure your individual kubernetes setup and also your organisation. There's also no one size fits all, this is just what works for us. Because of this - I'm confident that ambient mode will reduce the complexity for some operators, but runs the risk of increasing complexity for others (which I admit, could be the minority).
We run about 700 individual services ("workloads"). Each service:
- Runs in its own
Namespace - Runs with its own
Service Account - Has its own
Service - Is deployed by it's own isolated CI/CD pipeline
- Runs in a default-deny type setup from both an Istio and Network Policy perspective
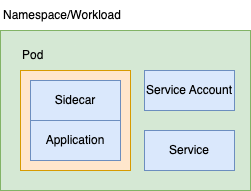
The namespace for us, is the workload boundary, It is a 1-2-1 relationship. And it's a hard and fast rule. Because of this, I do believe we'd end up with a waypoint proxy per namespace too. We wouldn't share a waypoint proxy across multiple workloads as we'd create coupling (risk/blast radius). Therefore we'd end up with something like this:
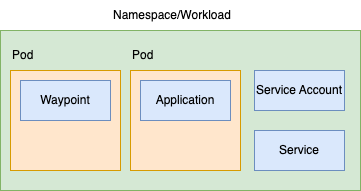
Instead of scaling a Sidecar, we'd be scaling a Waypoint - and that's what I mean by for us, it's sideways. We still have to think about scale of something.
Observability: It's just another container
This pretty much sums up how I feel about the Sidecar. It is just another container in your Workload. In order to effectively manage your costs ("right sizing"), there are key metrics that you should already be monitoring for your workload - that naturally extend to cover istio-proxy too. For me, these are:
- CPU and Memory Requests (eg. kube_pod_container_resource_requests)
- CPU and Memory Usage (eg. container_memory_working_set_bytes)
- CPU and Memory Calculated Utilisation (Usage / Requests).
Ignoring Istio for a moment, if you are not doing the above - you should. To help you out, here is the metric I use for Caluclated Utilisation of CPU:
- record: "container_cpu_usage_against_request:pod:rate1m"
expr: |
(
count(kube_pod_container_resource_requests{resource="cpu", container!=""}) by (container, pod, namespace)
*
avg(
irate(
container_cpu_usage_seconds_total{container!=""}[1m]
)
) by (container, pod, namespace)
)
/
avg(
avg_over_time(
kube_pod_container_resource_requests{resource="cpu", container!=""}[1m]
)
) by (container, pod, namespace) * 100
*
on(pod) group_left(workload) (
avg by (pod, workload) (
label_replace(kube_pod_info{created_by_kind=~"ReplicaSet|Job"}, "workload", "$1", "created_by_name", "^(.*)-([^-]+)$")
or
label_replace(kube_pod_info{created_by_kind=~"DaemonSet|StatefulSet"}, "workload", "$1", "created_by_name", "(.*)")
or
label_replace(kube_pod_info{created_by_kind="Node"}, "workload", "node", "", "")
or
label_replace(kube_pod_info{created_by_kind=""}, "workload", "none", "", "")
)
)You'll notice in this metric I also join on kube_pod_info which gives me some extra dimensions to my metric, particularly workload. This only works because we have that relationship of one deployment, to one namespace, which === one workload. This is optional, it just helps me view this metric at various levels, container, pod, node or workload. Doing this will inherently give you data for all your containers, naturally including your sidecar:
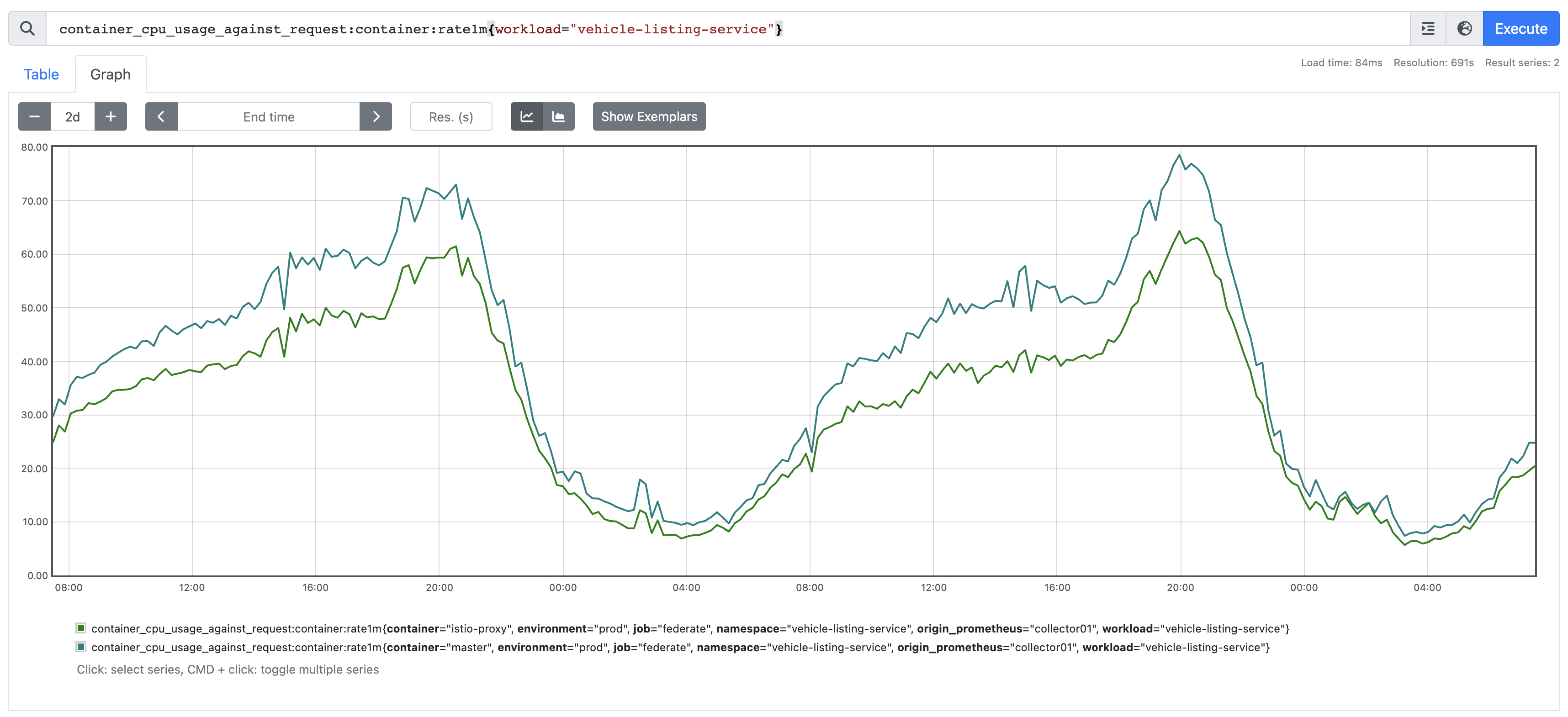
Sidecars Scale with your Workload
For HTTP workloads, we have observed that the Sidecar scales in a very similar fashion to the underlying application. You can see in the screenshot above how the "calculated utilisation" of the istio-proxy container closely follows that of the master container.
This is where I really like the Sidear pattern. Your Sidecar utilisation is tightly coupled to your Workloads utilisation, which is tightly coupled to the number of Replicas of your workload. In the above example; if we need horizontally scale the workload up or down, the % utilisation will stay roughly the same. Eg, you can see we peak at 75% for the master container, and 60% for istio-proxy, if we doubled the number of replicas, these two values would loosely half, but remain roughly aligned. We're only horizontally scaling one Deployment object, not two. We believe this is easier to reason with.
The guidance we give to our application owners is that we want Utilisation to sit around 75% at peak. Naturally here, folks ask why we don't auto scale. Auto scaling relies on compute being available from the underlying cloud provider. We had several customer impacting incidents where we couldn't scale up on demand because there were capacity issues with the underlying cloud provider. Also autoscaling carries a latency/lag, it struggles to respond to very sudden spikes, so it only effective on workloads with obvious gradual seasonality like we have above. We decided the cost savings associated with Auto Scaling do not warrant the risk that comes with not being able to reactively scale up to demand, and instead - we slightly over provision our workloads (hence 75%).
However if you're comfortable with Auto Scaling, you could set that target CPU on your Auto Scaling configuration and call it a day. You have a workload, and a closely correlated Sidecar that scale together.
This is where the Waypoint part breaks down for me. As in our setup we would have a waypoint proxy for every workload, we would create two separate isolated deployments that would need to be scaled differently, but in sync. It decouples something that for us, is inherently and intentionally coupled.
Setting the right values for CPU and Memory
In the example above you can see we've got a relatively healthy workload. The istio-proxy container has been given an amount of CPU which "fits" the workloads profile, and allows its utilisation to closely track that of the underlying application. Experience tells me that once you've got these two aligned, they down loosely stay aligned. The only time they would drift is if the performance profile of either container changed significantly (for example - if the developer made the application 2x as performant, utilisation for master would come down).
At AutoTrader, our platform team are responsible for building the "delivery platform", which our developers deploy apps on to, but the app developers are responsible for right-sizing their workloads (CPU and RAM). The platform team build tools that help them make informed decisions about these values.
What this translates to is a simple abstraction. We don't have our developers write 100x kubernetes manifests to deploy a workload. They don't care about Istio VirtualServices, or Sidecars, or Kubernetes Deployments, or remembering where to put annotations to get the scale of the sidecars right. Instead, we ask for a yaml file in their repo, which looks like this:
deployment:
istio:
resources:
cpu: 500m
memory: 80Mi
container:
replicas: 6
resources:
cpu: 1000m
memory: 956MiSo as you can see, the owner of the service is responsible for setting both the resources for their master container, and their istio-proxy. Our responsibility is to build tooling that helps them making informed decisions when picking these values.
You've seen how we do that with Metrics such as Utilisation above, which we present in Grafana dashboard, but we also do something called "Suggestions". These are tips that we give application owners on optimally configuring their services:
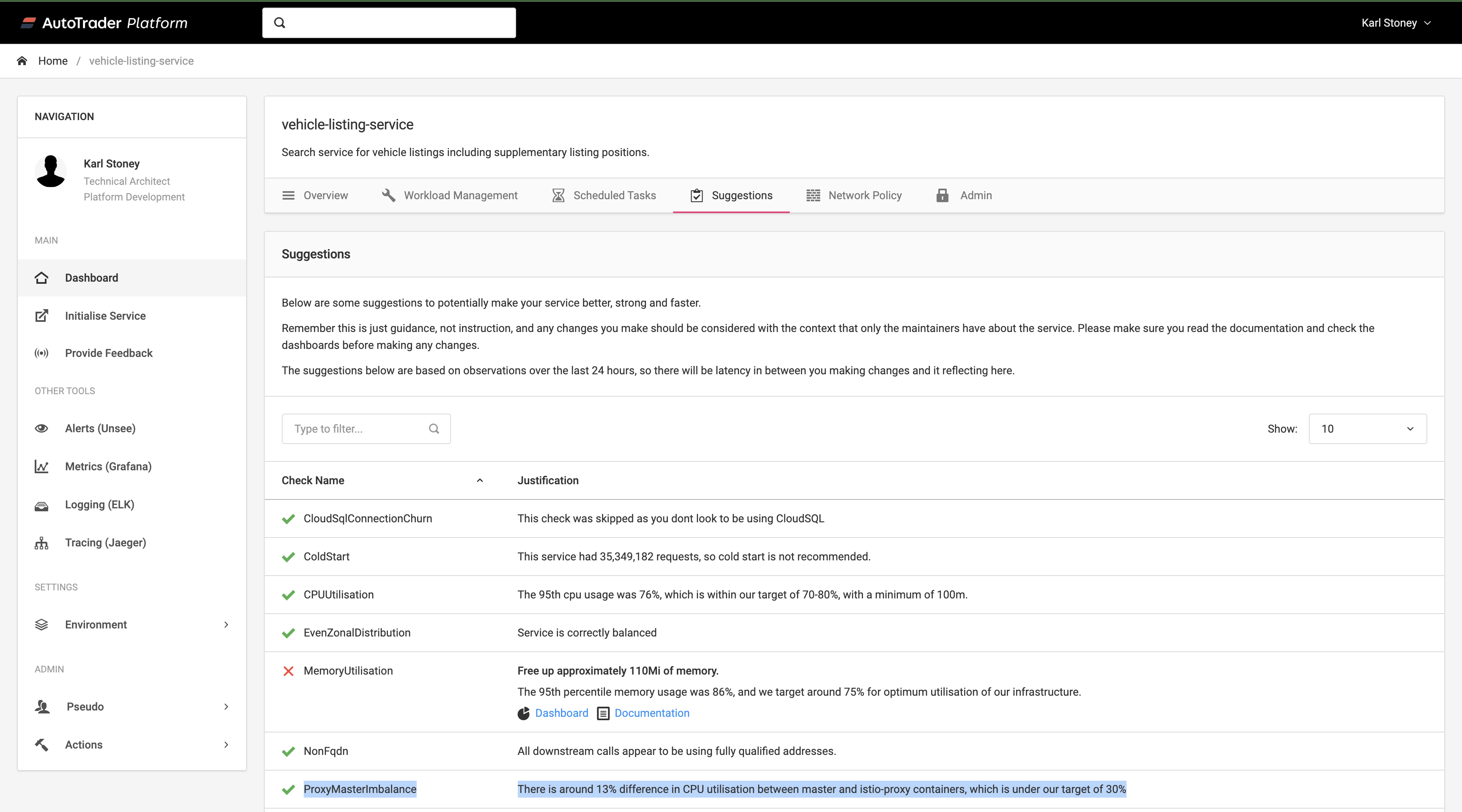
So you can see here we have one called ProxyMasterImbalance. This suggestion would be active if we detect more than a 30% drift between the master and istio-proxy container within a given workload. Here's an example of that suggestion firing:

Summary
Hopefully you can see here how sizing the sidecar can fit quite easily into your existing business processes for sizing your workload. You should be doing this anyway, for healthy ustilisation of your infrastructure.
We've built a culture where squads care for and own their software in production environments and that includes key CFRs such as cost. They know they're contributing towards the bigger picture by staying on top of these things and on the whole, they do it. Critically, they already care about their master container utilisation, so istio-proxy is just one additional container that they have to set 2 values for (cpu/ram), and we provide data to make that as easy as possible, and in the vast majority of situations - it's something you only need to adjust once.
I do also want to call out that this post is specifically thinking about scale. There are other potential advantages to separating out the proxy from the app (such as isolated upgrades). Again though I personally feel this comes with pros and cons (like most decisions in tech), but that's a blog post for another day.