Managing Services: Metadata
Capturing, validating, storing and discovering service metadata. Keeping that metadata consistent across numerous integration points.

I've tweeted a few times over the past year or two about how we manage services at Auto Trader. I even did a quick high level blog on it a while ago. It's evolved a lot in that time, the engineering organisation has changed shape quite drastically too. The capabilities we've added have had to be flexible enough to adapt rapidly to that change. Things have settled somewhat now, so I felt like a refreshed and slightly more in depth blog (or two) was due.
For those who don't follow my ramblings on Twitter, here's a bit of background about Auto Traders platform.
- There are around 450 different services deployed on our platform. Split around 60% Java, 20% NodeJS, 20 % other (python, golang, etc).
- All applications are deployed via CI/CD and run on Kubernetes, we have an in-house built tool called
Shipprthat manages that gap between the CI/CD tool and Kubernetes. - We have the ability to mass rollout all applications if we want to pull in things like Java patch updates, or base image updates. Perhaps rollout new Istio sidecars, or push out important security patches.
- Anyone is empowered to quickly deploy new services, or get rid of old ones. On average we create 3-5 new services a week.
- About 30% of our pipelines are Continuous Delivery. Each commit that is pushed automatically ends up in Production without interaction. The rest are manually triggered to Production, but the teams typically operate on a deploy-small, deploy-often mentality.
The result of this is that we deploy into Production environments anywhere between 250 and 500 times per day (586 being our current peak).
This all sounds wonderful, but it certainly comes with challenges too, for example:
- How do we discover services? Believe it or not we've had several different teams in totally disconnected areas of the business build the same thing in the past.
- When things go wrong, because let's face it, they do - how do we quickly tell the right people about the issue?
- How do we make sure all these services are kept up to date, patched, maintained?
- How do we ensure consistent metadata across lots of different systems (CI/CD, GitHub, Slack, Azure, etc)?
- And in the spirit of "platform thinking" - how do we automate away as much of this as possible, to reduce the cost of building and managing micro-services.
We've built a lot of custom tooling over the years to solve some of these problems, but none of them work without first capturing Metadata and applying it consistently, so that's what I'm going to start by covering today.
What Constitutes Metadata?
Great question! The answer for us has evolved over time. Metadata for us is broken down into two parts, user-specified metadata, and dynamically generated.
Looking at user-specified first - these fields are mandatory for any application that gets deployed on the platform:
serviceDiscovery:
name: the name of the service
description: A brief description of the service
serviceTier: 1, 2 or 3
owner: [email protected]
maintainers:
- [email protected]
contributors:
- [email protected]
They're all pretty self explanatory, apart from Service Tier. We group all of our applications into tiers, which helps control aspects of automation downstream:
- Tier 1: A key service, deployed to multiple regions, multiple AZs
- Tier 2: A key service, deployed to a single region, multiple AZs
- Tier 3: A 9-5 service, deployed to a single region, multiple AZs, not monitored outside of normal business hours
You're probably also asking the differences between the user types, they are:
owner- This is generally the Tech Lead. The ultimate person of responsibility.maintainers- These are the group of people who can be considered "admins" on the service, they actively maintain it, will fix bugs, handle alerts, deal with incidents etccontributors- These are people that occasionally dip into the service, they push code and need SSO access, but nothing administrative.
I will go into more detail about how we use these values later.
At deploy time, Shippr adds some dynamic metadata to this as well which it infers from looking at the Dockerfile, as well as the CI/CD environment:
serviceDiscovery
baseImage: platform-base-java17
git:
lastCommitter: [email protected]
revision: b1d6f48104d891a06f5bb51efdd2d25a553584eb
url: https://path-to-github/repo
gocd:
counter: 1234
name: pipeline-name
stage: non-prod
triggeredBy: changesWhere to store the Metadata?
We have a yaml file in the root of all git repositories which contains the user-specified information above. Shippr then reads that metadata, adds the dynamic bits, and converts it into a CustomResource that gets stored in the namespace of application being deployed. We like this approach because it makes a statement that the service metadata is a deployable artefact and is just as important as the Deployment, Service, Ingress etc.
Remember we use Kubernetes, which is effectively a big extensible API. In your environment, you could have a simple metadata service to store this information.
How to enforce the Metadata?
Enforcing metadata comes down to two areas for us, schema validation and then data validation.
One advantage to using Kubernetes to eventually store the data is that we have a Json schema on the CustomResourceDefinition. Kubernetes will validate the incoming request against that schema and reject the request if it doesn't match. This is great as it covers both the user input, and dynamic metadata.
Shippr also has a JSON Schema which is used to validate the user input is structured correctly. That same schema is used to generate a documentation site, where users can go and see the options available to them. The pipelines fail if the data they've input is invalid. That's their contract to the platform.
There's a certain level of data validation we can do in that schema with enums, for example ensuring serviceTier is 1, 2 or 3.
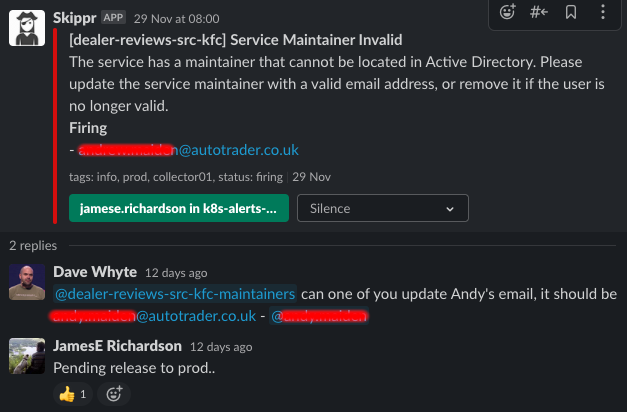
The next challenge though is on going data validation against another system, what I mean by this is how do we know [email protected] is a valid user? What happens if they leave the organisation? We actually do this at runtime with another service called sweepr. sweepr continually and periodically validates the CustomResource objects deployed to the cluster and validates that the owner, contributors and maintainers fields match up to actual users in our Identity system.
When the user is invalid, a slack alert gets fired, tagging the service owners and prompting them to fix the issue:
How to visualise Metadata
So you've got your service metadata stored. You know the quality of that metadata is good as you validate both the structure and the data. But how do you surface it?
Well in our case because we store it in kubernetes, we can access it via the command line like any other resource:
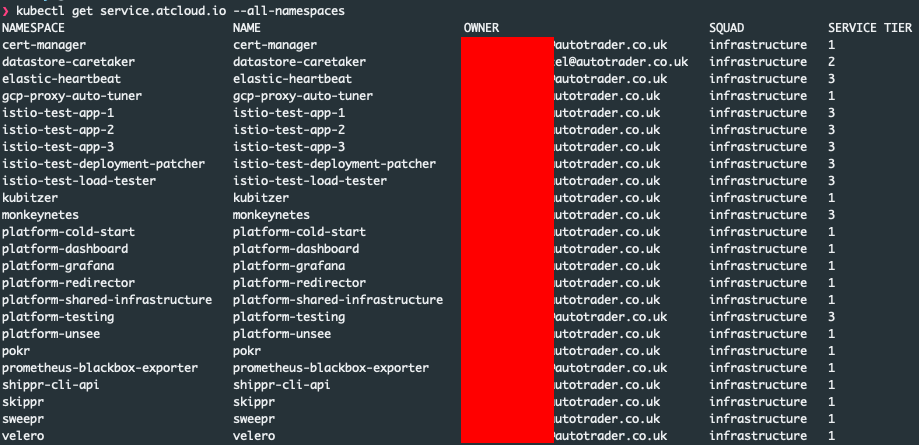
This is great, because if you're debugging a problem and you quickly want to know who owns it, you can get it with a simple kubectl command.
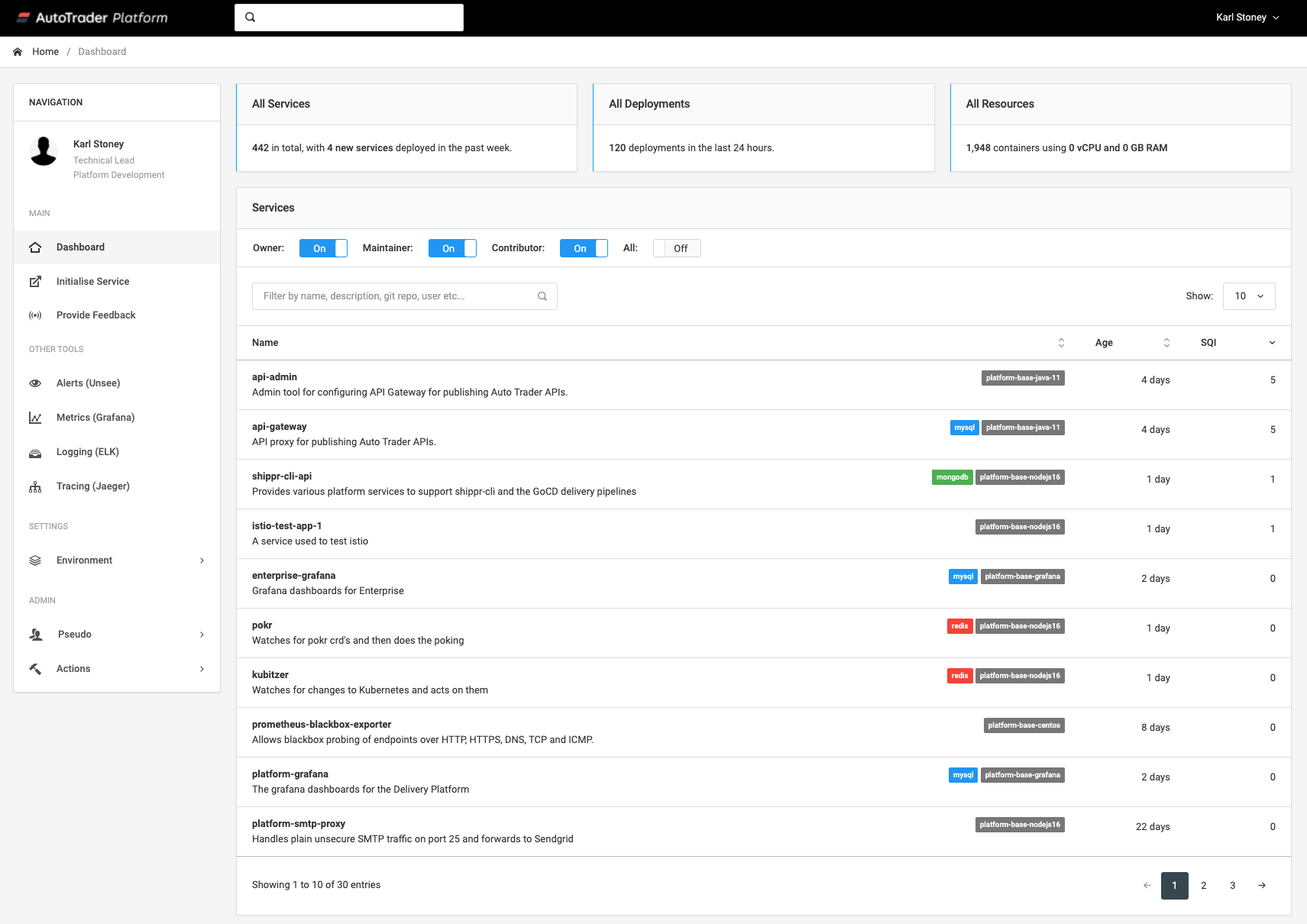
However that only works for people with command line access to the kubernetes cluster, which very few of our users have. We decided to build a simple user interface on top of the data called platform-dashboard. This uses Kubernetes as an API server for the metadata, and visualises it in an easy to access way. Here you can see the top level view of the services. You can quickly filter to discover services by their description, language, name, owner etc.
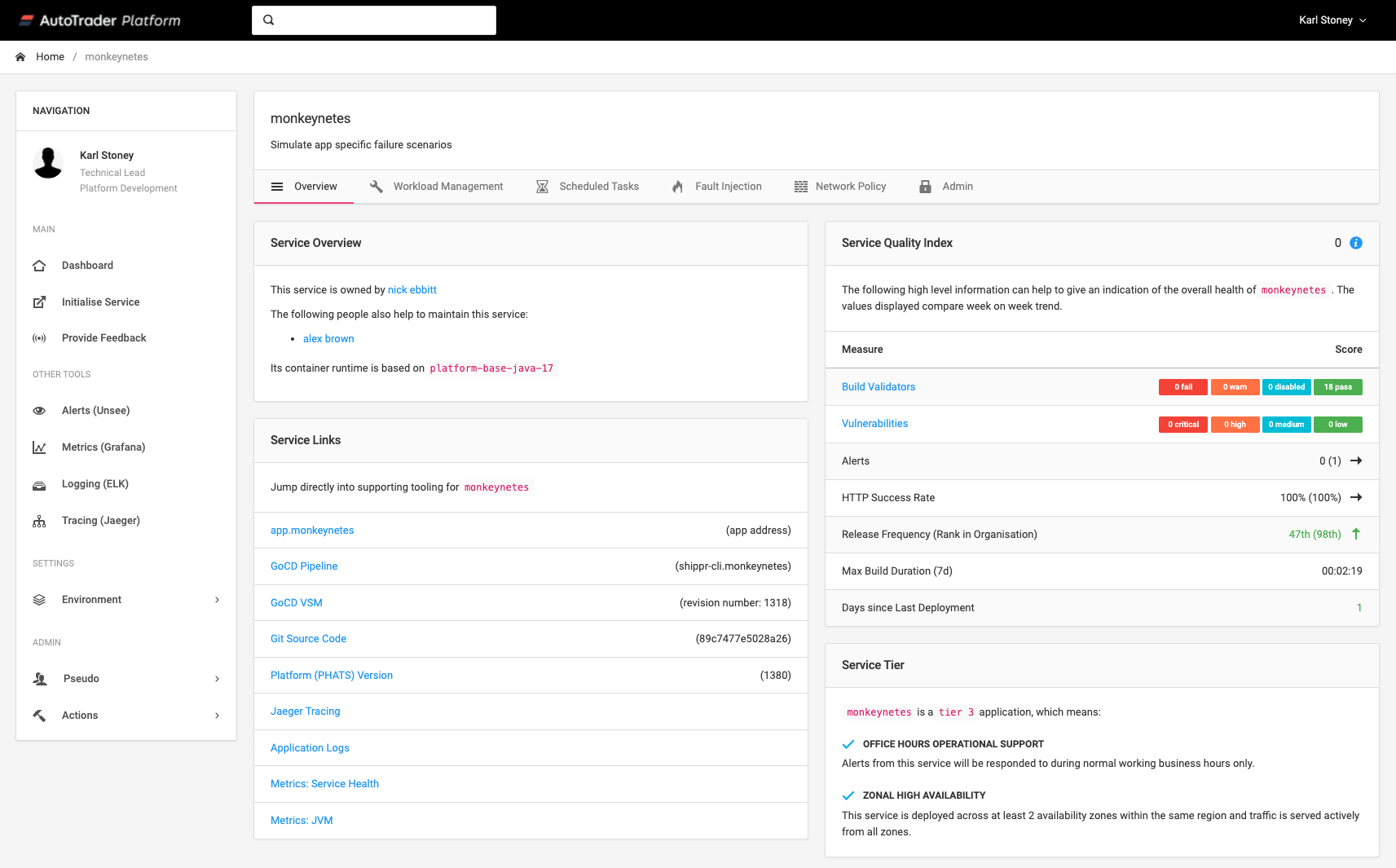
Here you can see me drilling into monkeynetes. Note how we use the dynamic metadata like gocd and git to generate useful Service Links off to the pipieline, and git commit used during that deployment?
Consistent Metadata across Disparate Systems
We see this resource as the source of truth for who the owners, maintainers and contributors are for a given system. But this concept exists in lots of places, for example:
GitHubrepository permissions- SSO access to the service via
Azure Security Groups SlackUserGroups
We move people around quite regularly at Auto Trader, so it was very easy for these systems to become out of sync, there was also a lot of wasted time spent from admins updating groups for 400+ services. So we wrote a simple system to take the CustomResource above and use it to reconcile the other systems.
Again a quick reminder that we use Kubernetes to store this data, so in our implementation we use Kubernetes Watch semantics to write a simple Controller that watches for when the resource changing, and reconciles GitHub, Azure and Slack. If you wrote a simple metadata service instead, that would be responsible for the reconciliation.
These are the actions we perform for each of the different user types:
ownerandmaintainerare considered repo admins, they're added to aservice-name-maintainersgroup, and givenMaintainpermissions on the repository.contributorsare considered writers, and givenWritepermissions on the repository
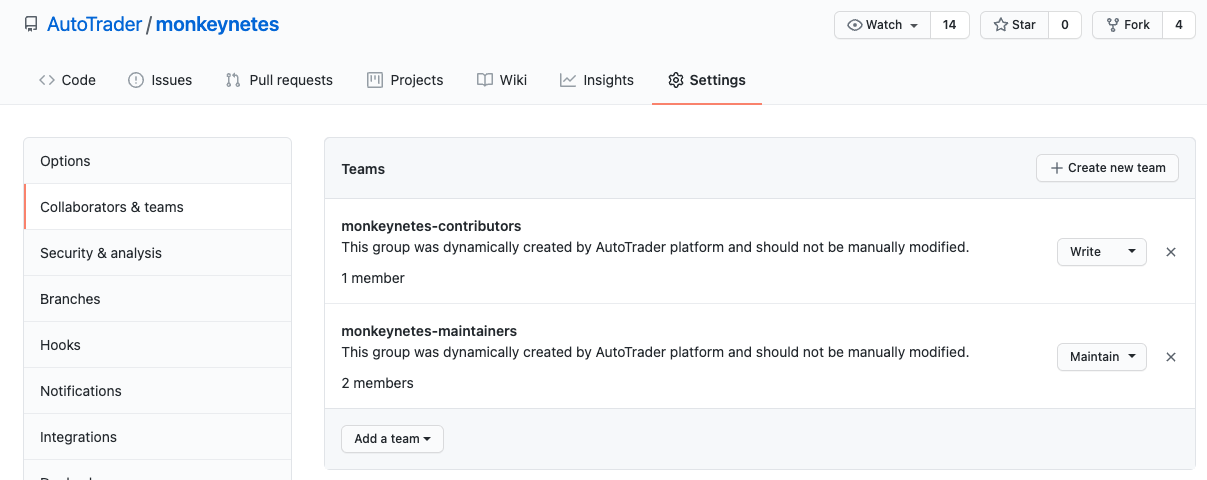
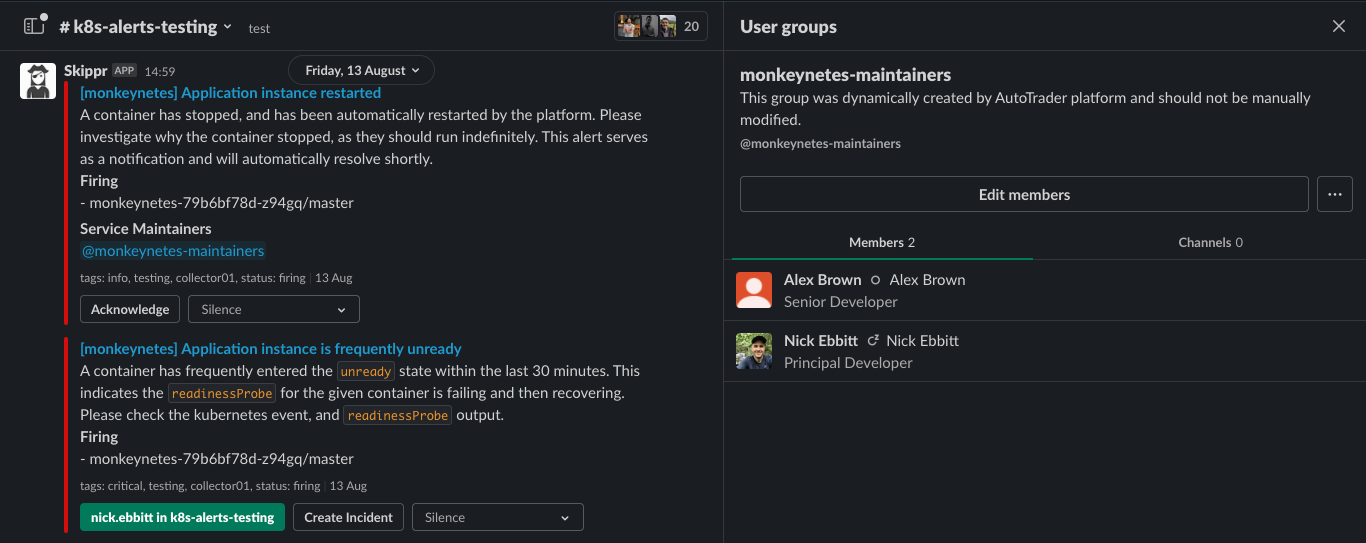
maintainersare expected to respond to alerts and incidents for a given service, and be easily reachable via slack. So the service will create a Slack User Group which means them easily taggable as@service-name-maintainers:
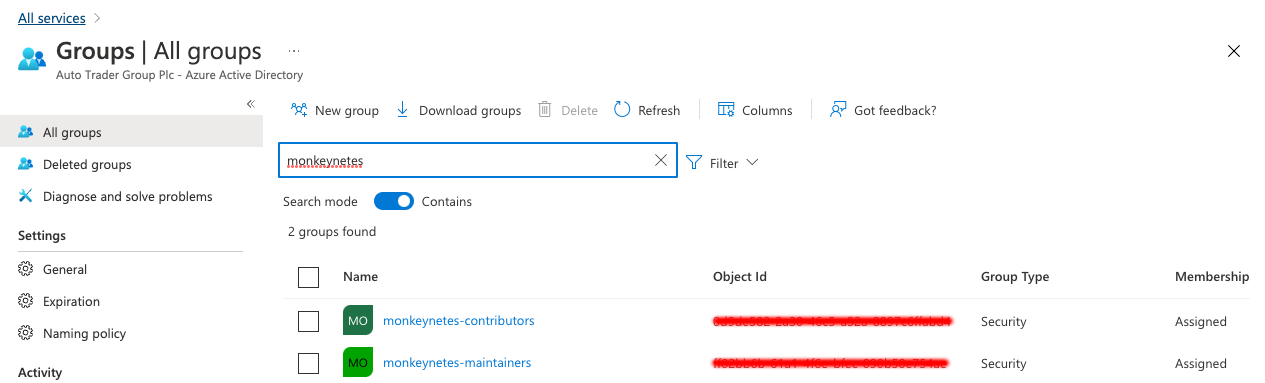
- We create two security groups in
Azurewhich teams can use for AuthN/AuthZ, SSO to their service etc:
What this means is that we're able to consistently update numerous systems by updating one file stored in Git. It means that when someone needs access to a new system they simply send a PR to the system they're wanting to work on, and when access needs to be revoked, it's revoked consistently.
Conclusion
Hopefully this blog helps you to see how storing just a little bit of metadata about your services can make a vast application estate so much more manageable.
In the next article, I'll be showing how we use that metadata to enrich our alerting an incident process to help get the right eyes on a problem as quickly as possible.