Kubernetes Service Discovery
Storing rich metadata as Custom Resources on the Kubernetes API to enable Service Discovery.

This post it outdated, and left here for SEO reasons only! It's been superseded by managing-services-metadata, so read that instead! :)
One of the simplest things we've done at AutoTrader that's had huge impact is ensuring that our services are easily discoverable, with rich metadata.
When you have a large organisation, if services aren't discoverable - you'll end up with disparate teams building services that look very similar. True store: Once upon a time, we had 5 different services whose function was to lookup postcodes!
Also during incidents, historically we lost a lot of time finding out the basics like who owns the service, when it was last deployed, what version is currently deployed, who committed in that deployment and so on.
All of this is just metadata associated to a deployed service, some of which is provided by the teams, others you infer at deployment time. We wanted to surface it as quickly as possible.
Options We Considered
There are lots of different approaches for tackling this problem. One of the more common is to use annotations on the kubernetes resources which are arbitrary key/value(string) pairs. We decided against this because:
- A single service will have many (sometimes different) resources associated to it. Annotating them all seems wasteful, but only annotation specific resources makes discoverability harder.
- We want to store a relatively large amount of a metadata
- We want to be able to watch for changes specifically to metadata
- We wanted to be able to constrain the input with JSON Schema and store types other than strings
Another approach is to have a separate service and datastore responsible for tracking this information, we decided against this because:
- We wanted to be able to inspect the service metadata on the kubernetes cluster, using kubectl
- We didn't want to build and manage another system
- We wanted the resources to be tied to the application deployment as a first class citizen
As a result we decided to use Kubernetes Custom Resources.
Creating a Custom Resource Definition
Custom resources allow you to extend the kubernetes API with new types. Think about your Deployment, Pod, StatefulSet etc. They're all just data types, and you can add your own. So in our case we wanted to add a service.atcloud.io, that's trivially done with a manifest like this:
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
name: services.atcloud.io
spec:
conversion:
strategy: None
group: atcloud.io
names:
kind: Service
listKind: ServiceList
plural: services
singular: service
scope: Namespaced
versions:
- name: v1
served: true
storage: true
schema:
openAPIV3Schema:
type: object
properties:
spec:
x-kubernetes-preserve-unknown-fields: true
type: object
properties:
name:
description: The display name for the application
type: string
description:
description: A brief description of the application
type: stringObviously this is a pretty trivial example, we capture all sorts of information like the owner, the squad etc. Apply this to your cluster, and just like magic you'll be able to access that type via kubectl:
❯ kubectl get services.atcloud.io
No resources found in default namespace.Creating a Custom Resource
Now you've defined the schema, you can start creating resources to track your metadata.
apiVersion: atcloud.io/v1
kind: Service
metadata:
name: skippr
namespace: skippr
spec:
description: Skippr receives alerts from prometheus-alertmanager, enriches them, and forwards them on to slack and pagerduty
name: skipprLets get that resource:
❯ kubectl -n skippr get service.atcloud.io
NAME OWNER SQUAD
skippr Karl Stoney infrastructure Great! Something you might have noticed here is that we've got OWNER and SQUAD being printed out by kubectl. These are defined in your CustomResourceDefinition by adding additional printer columns, like this:
spec:
versions:
- name: v1
additionalPrinterColumns:
- description: Application Owner
jsonPath: .spec.owner
name: Owner
type: string
- description: Squad responsible for application
jsonPath: .spec.squad
name: Squad
type: stringOne thing to note, we don't expect our teams to write kubernetes manifests. We have a separate abstraction based on Helm over the top of this. We only expect product teams to provide a simple serviceDiscovery block, which we map to the above CRD:
serviceDiscovery:
name: skippr
description: Skippr receives alerts from prometheus-alertmanager, enriches them, and forwards them on to slack and pagerduty
owner: Karl StoneyDeploy time Dynamic Data
As I showed above, we expect product teams to provide a simple serviceDiscovery block in their values file, which we map to a CRD. But then at deployment time, our CI and CD tooling injects a whole load of deploy time dynamic data. We have a custom CLI which wraps helm, and injects these values. Here's an example of the complete CRD once it's gone through CI:
apiVersion: atcloud.io/v1
kind: Service
metadata:
name: skippr
namespace: skippr
spec:
baseImage: platform-base-nodejs14
datastores:
- redis
description: Skippr receives alerts from prometheus-alertmanager, enriches them, and forwards them on to slack and pagerduty
them.
git:
lastCommitter: [email protected]
revision: b1d6f48104d891a06f5bb51efdd2d25a553584eb
url: https://github.atcloud.io/AutoTrader/skippr
gocd:
counter: 1385
name: shippr-cli.skippr
stage: non-prod
triggeredBy: changes
hosts:
- app.skippr.testing.k8.atcloud.io
modifiedOn: "2021-04-26T15:35:47.455Z"
name: skippr
owner: Karl Stoney
serviceTier: 1
squad: infrastructure
type: nodejs
versions:
phats: 0.1.1133Surfacing the Data
At AutoTrader, not everyone has access to the Kubernetes cluster. In fact many of our developers are blissfully unaware we're using Kubernetes at all. As a result, we knocked together a relatively simple Platform Dashboard which queries the Kubernetes api for the service.atcloud.io objects directly:
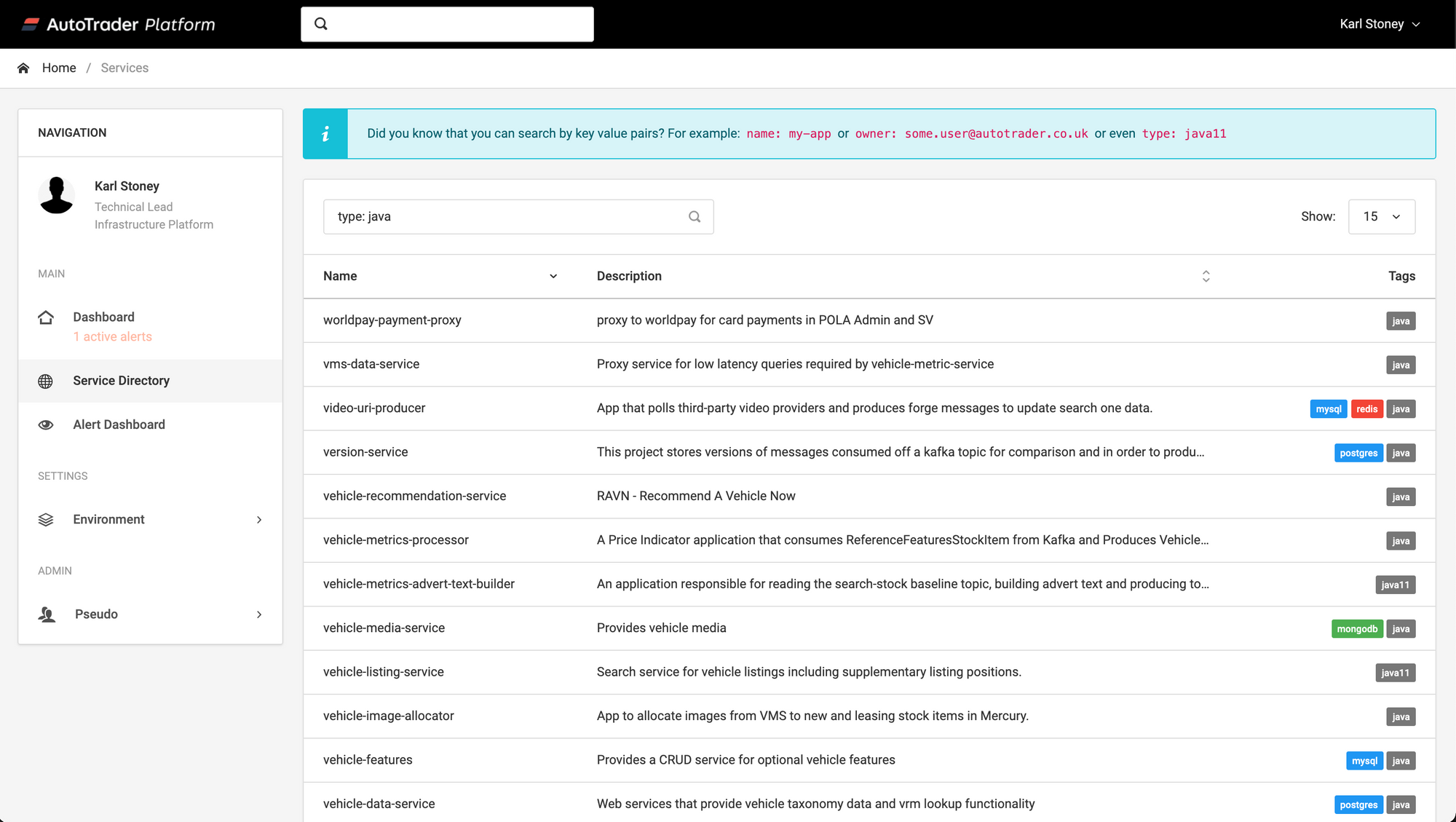
All this is effectively doing is the equivalent of kubectl get services.atcloud.io --all-namespaces and then displaying it in a table. You can then quickly free text search across all services to see if something you want, already exists.
You can then click onto the service, to view much more information:
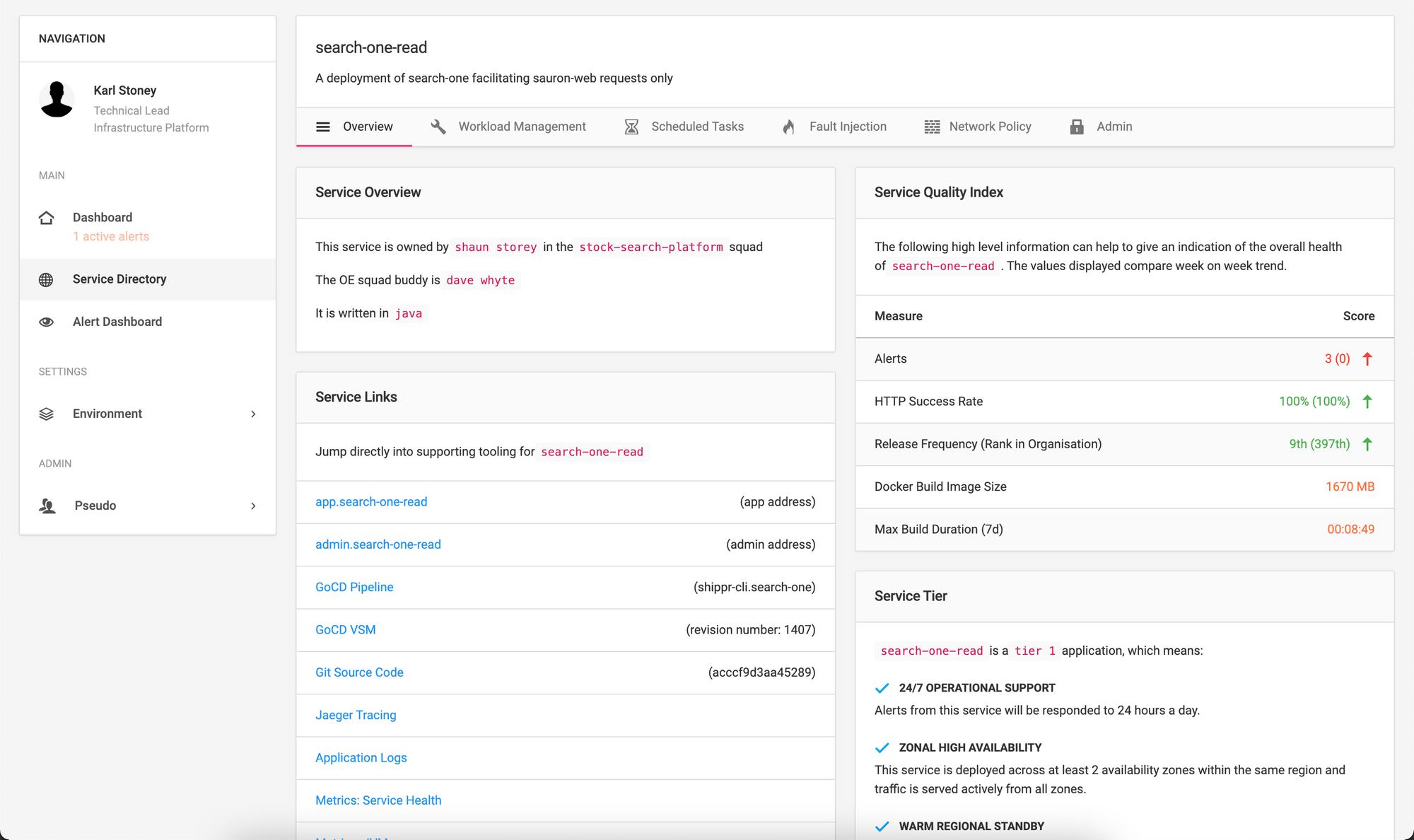
The most useful aspect of this page is the Service Links section. You'll not that we have links off to the following:
- GoCD VSM: This is the specific pipeline that deployed this instance of the application to the cluster
- Git Source Code: This is the specific commit that has been deployed
- Jager/Logs/Metrics: Direct links to observability tooling for this release.
Other uses for the Metadata
Once the metadata is in place, you can start to enrich other business processes with it. For example; the application above (Skippr) acts as intermediary between Prometheus AlertManager, and Slack. It receives incoming Prometheus alerts and "Enriches" the with various information, before forwarding onto Slack.
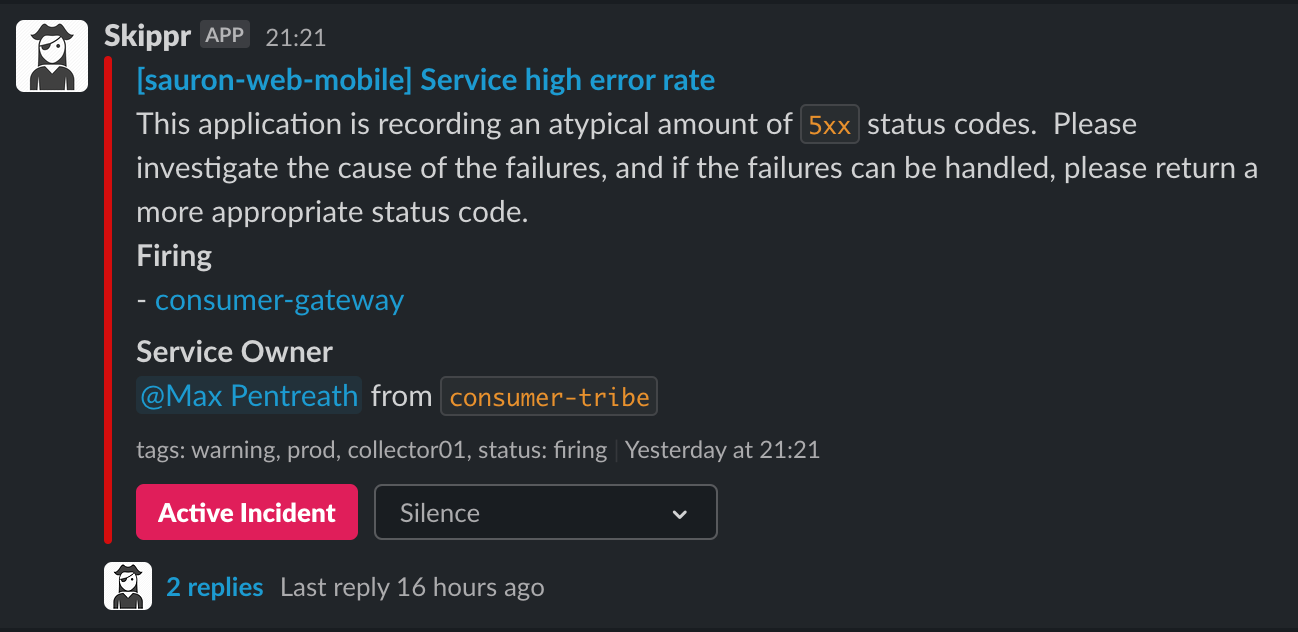
Immediately here you can see that because sauron-web-mobile has a service.atcloud.io object, we were able to enrich that alert with the service owner, and tag them to let them know there's an issue with the service that they own.
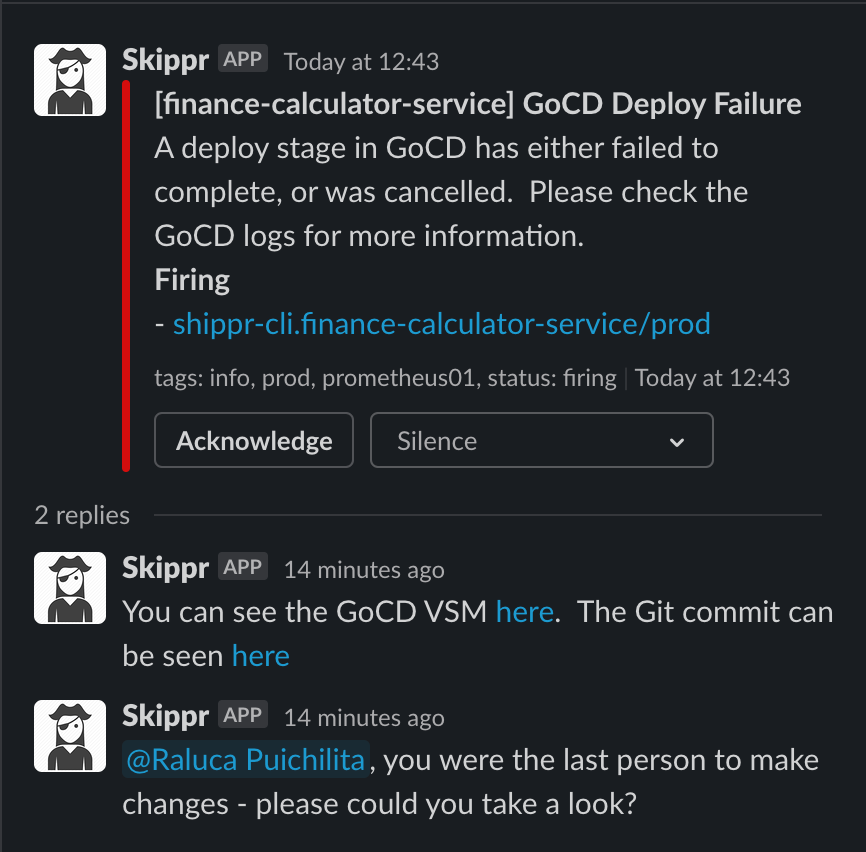
Here you can see the lastCommitter service information being used to tag the person who broke the build. You can see links directly to the GoCD VSM and the Git Commit both being pulled from the service.atcloud.io object.
Conclusion
Hopefully this shows you some of the rich user experiences you can build once you start capturing service metadata, with relatively little effort.