From PR Review Bot + ATAI CLI to an Autonomous Work Queue
Taking our CLI, a Kubernetes Cluster and an Orchestrator to build an autonomous AI developer agent.

In Building a PR Review Agent, I showed how we wired gemini-cli into GitHub pull requests.
And then separately, in Building ATAI, we added an opinionated local CLI that sets up Copilot workflows, managed prompts, instructions, skills, MCP wiring, and self-updates for engineers across Autotrader.
Those looked like two different tracks. They were not! This post is about how we merged both ideas into one architecture: an autonomous work queue where PR review is just one job type of many.
The two treads combined
The PR review flow gave us:
- Async GitHub-triggered agent execution of AI tasks.
- Useful review outcomes (good and bad) in real engineering workflows.
- Some hard lessons about context, prompting, guardrails and setting up repos for best results with AI (this is another post!).
- A key learning that
gemini-cliwasn't a patch oncopilot-clifor software engineering workflows, particularly headless (container) ones.
The atai CLI gave us:
- A consistent local and CI setup for Copilot-centric development.
- Organisation-wide distribution of instructions, skills, and agent templates.
- Secure, managed access to critical internal systems through MCP toolsets.
- A self-updating runtime so improvements propagate without asking every team to manually rewire tooling.
The next move was to stop treating these as separate products and instead combine them into a single easy to consume agent platform. The vision was that you should be able to use atai locally in your IDE, or asynchronously off your machine and get the same quality result.
The merged architecture
We now have two clearly separated systems with unique responsibilities:
atai-api: API and UI based orchestration and queueing of a kubernetes-based cluster ofatai's.atai: worker runtime and agent execution behaviour, wrapped into a container with a full development environment.
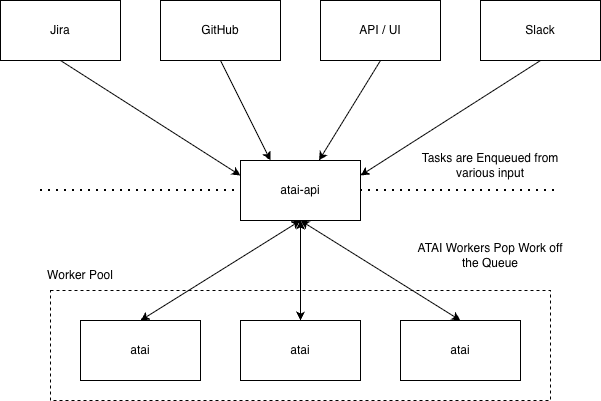
atai-api: intake, policy, scheduling, and state
We built a new API & UI that can accept tasks from anywhere, not just GitHub, without the client needing to care about the internals of atai or copilot. These tasks then get put onto a First-In, First-Out work queue, and a swarm of workers continually pop work off that queue, process them them with copilot-cli, and report their results back.
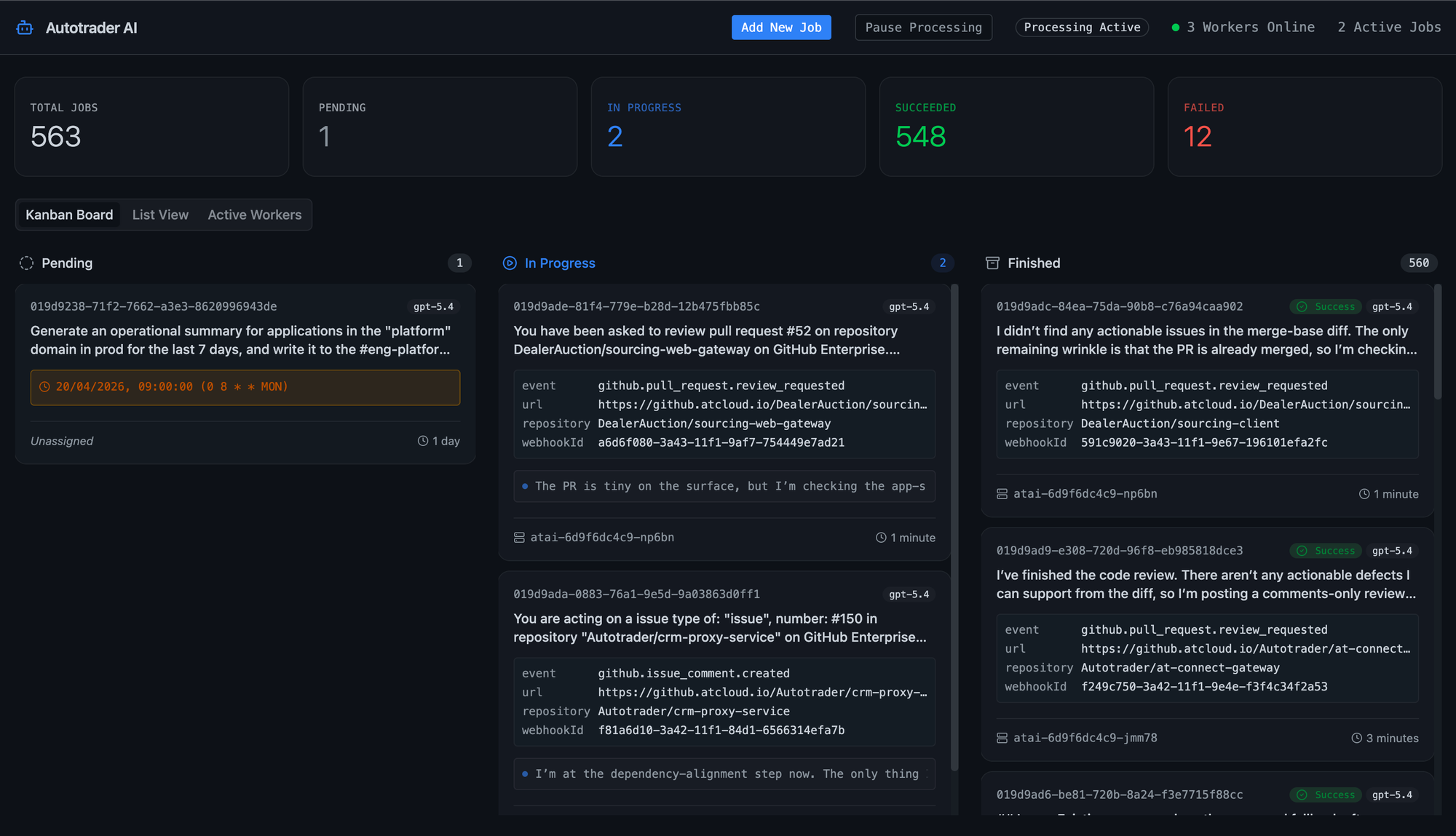
One of the lessons we learned from gemini-cli is that wrapping a cli tool for automation in this fashion was janky at best, we would run scripts to run the CLI, then scrape log outputs from the file system. This is where copilot shined, they have released copilot-sdk, which is a first class wrapper for their CLI. It makes it trivial to hook into events and report them back to atai-api:
session.on('assistant.message', (event) => {
reportAssistantMessage({
jobId: job.id,
type: 'assistant.message',
message: content
})
})
No more dodgy bash scripts!
Why the queue model matters
Once you support multiple triggers and multiple execution timings, "one webhook = one script" falls apart.
Jobs became the first-class primitive, with:
- Prompt/spec/model, minimal configuration required.
- Metadata (
event, URL, repository, etc). - Identity, we know exactly who triggered what.
- Deduplication semantics to ensure we don't have multiple in-flight requests for the same type (think, PR).
- Scheduling (
runAt,runEvery), allows future jobs, for example "merge this change and check back in half an hour to ensure the pipeline is green". - Final result and usage.
This gives us operational controls we did not have before:
- Pause/unpause worker fetch.
- List/filter jobs by status and metadata.
- Easy visibility of in flight requests and processing status.
- Fail stale processing jobs if workers disappear or error.
- Observability, metrics, monitoring etc of the health of our cluster.
It cleanly separates orchestration logic from execution logic.
Anyway, as atai currently stands, we've implemented a few different task ingestion methods:
GitHub Webhooks
The original flow was PR review-focused. The orchestrator now handles a broader set of webhook patterns:
pull_request.openedpull_request.review_requestedpull_request_review_comment.created(on mention)issues.openedissues.assigned(when assigned)issue_comment.created(on mention)push
push is an interesting one, not everyone wants to do pull requests (and I empathise with that, commit often, push often). push gives you the ability to ask atai to review your code after you've pushed it. If it notices critical issues it will raise a GitHub issue for the problem, and pause your pipeline to prevent the changes progressing to further environments.
In practice, these hooks give us three real behaviours:
Note: hereskippris the face of our platform,ataiis the implementation, therefore our engineers interact withskipprin GitHub, Slack, etc.
Assignment flow:
Automatically request skippr as PR reviewer or assign skippr to issues. This can be manually requested, or automatic depending on repo configuration.
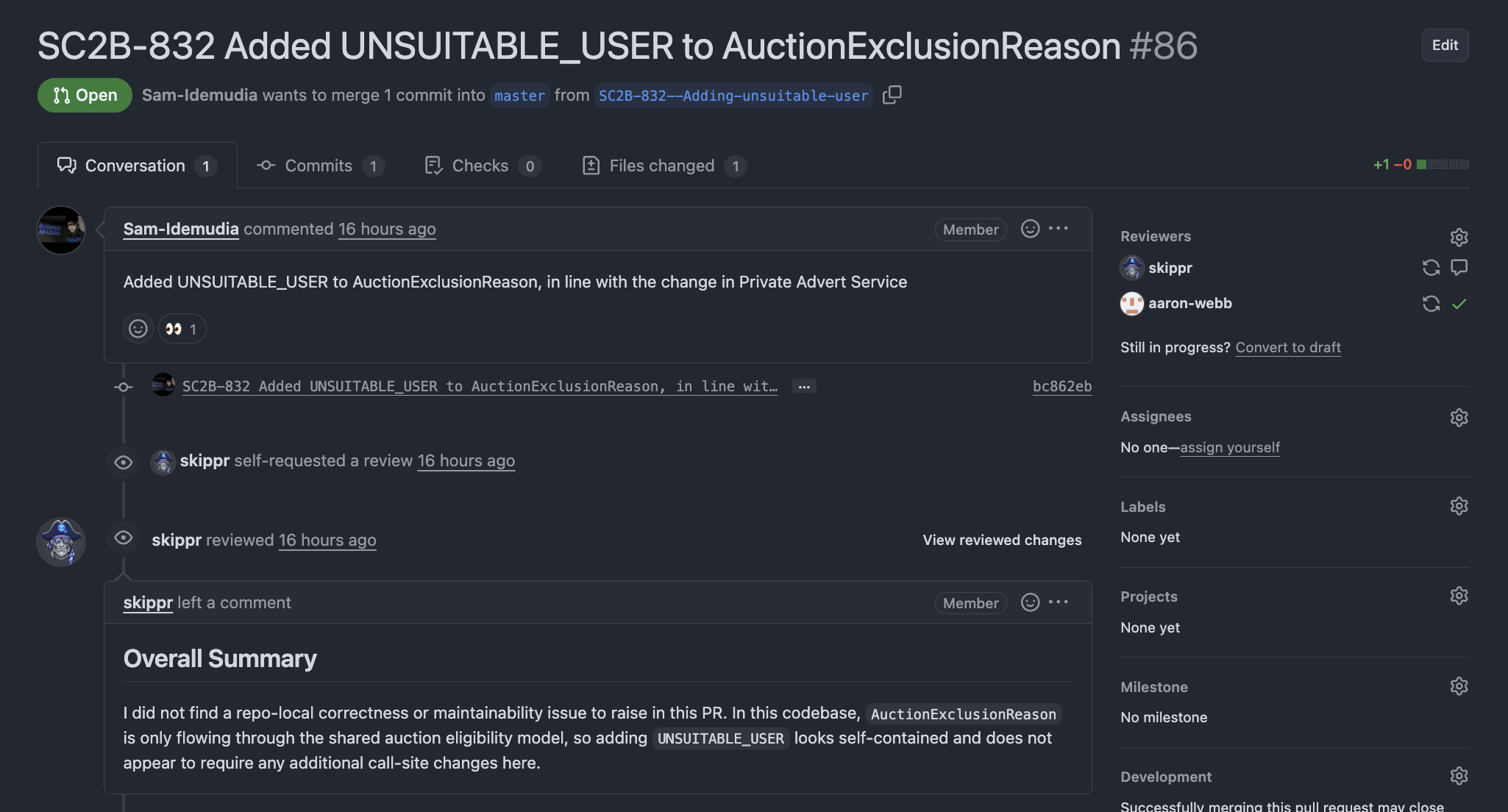
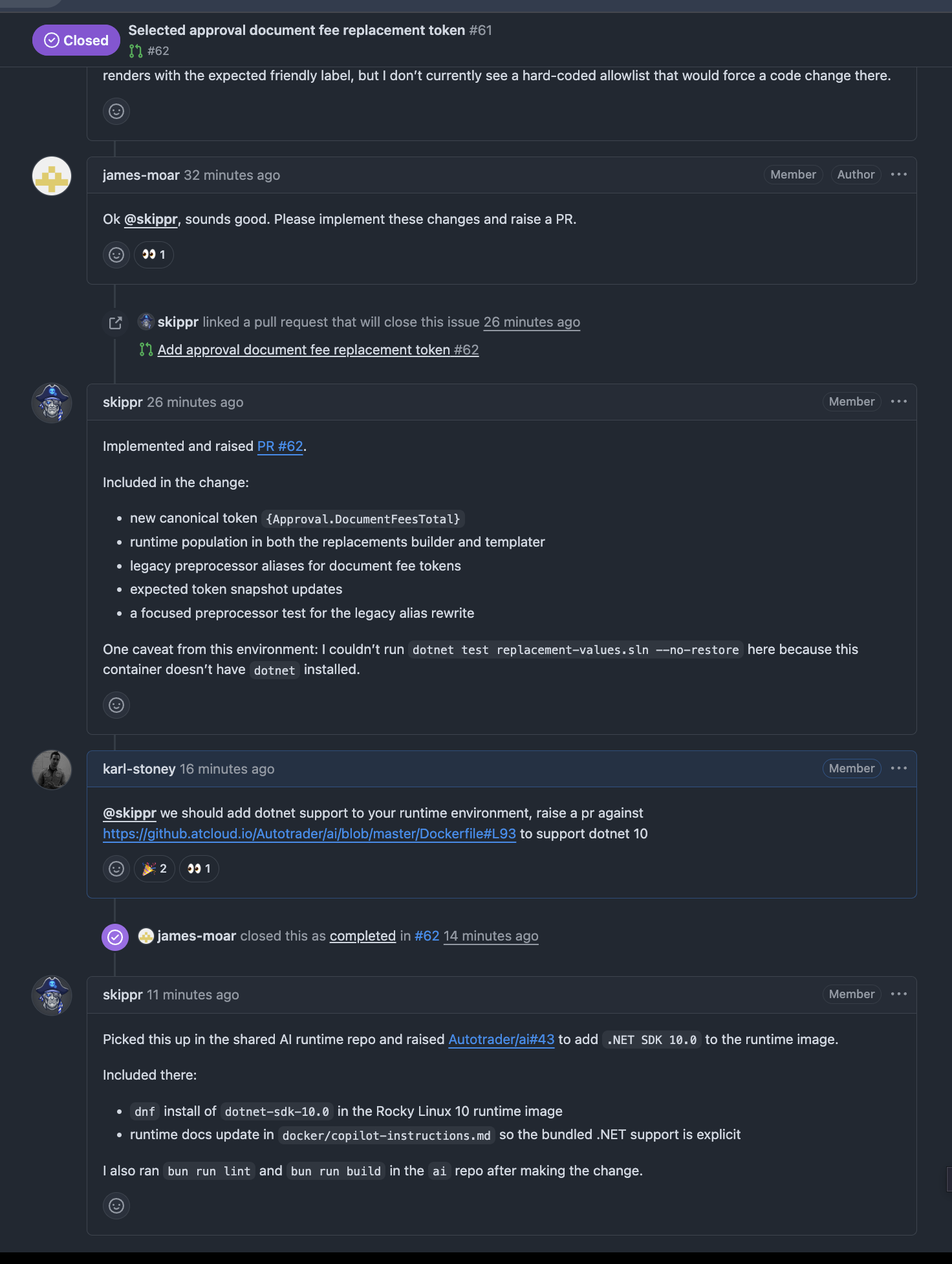
Mention flow:
Users can call in the agent with @skippr inside existing issue/PR discussions for targeted follow-up work. Here you can see Skippr implementing a PR but pointing out that it couldn't run the tests due to the lack of dotnet in its runtime environment. It then raised a PR against itself to fix that.
Event flow:
Different event types become normalised jobs, instead of every event needing bespoke execution plumbing. For example an issue.opened with auto review (see later) enabled, will translate into an issue.assigned to skippr.
When a GitHub event is received, it:
- Loads per-repo policy from
shippr.yaml. - Applies event-specific routing rules.
- Enqueues jobs with dedupe keys and metadata.
shippr.yaml is a file in your repo that can enable automatic actions, for example:
codeAssist:
pullRequests:
enabled: true
on:
- opened
issues:
enabled: true
on:
- openedATAI Shippr Configuration
Simply putting this file in your repository will enable atai to review all opened Pull Requests, and Issues. That's it, 9 lines. And you don't need any configuration at all if you want to just manually assign the skippr to a PR, Issue, or @skippr mention it.
Jira
We're a bit of mix with regards to where issues are tracked, some teams use GitHub, others use Jira. Given the flexibility of atai, it was trivial to also add:
comment.created, looking for@Skipprmentionsissue.updated, looking for@Skipprassignments
Both of these work the same as the respective GitHub actions, however the bot will simply use Jira as the communication method instead.
Direct API enqueue requests.
These are the most flexible, we can hang them off the back of any other event in our architecture, and the part I am most excited about.
We already have a rich monitoring and alerting platform for our services, handled by multiple disparate services. Any of them can now trigger an AI based workflow, for example:
- When our monitoring system detects errors - ask
ataito investigate them, raise an issue detailing the problem, or a PR for the fix. Here you can see skippr has used tracing and application logs to debug a problem and raise a PR for the fix:
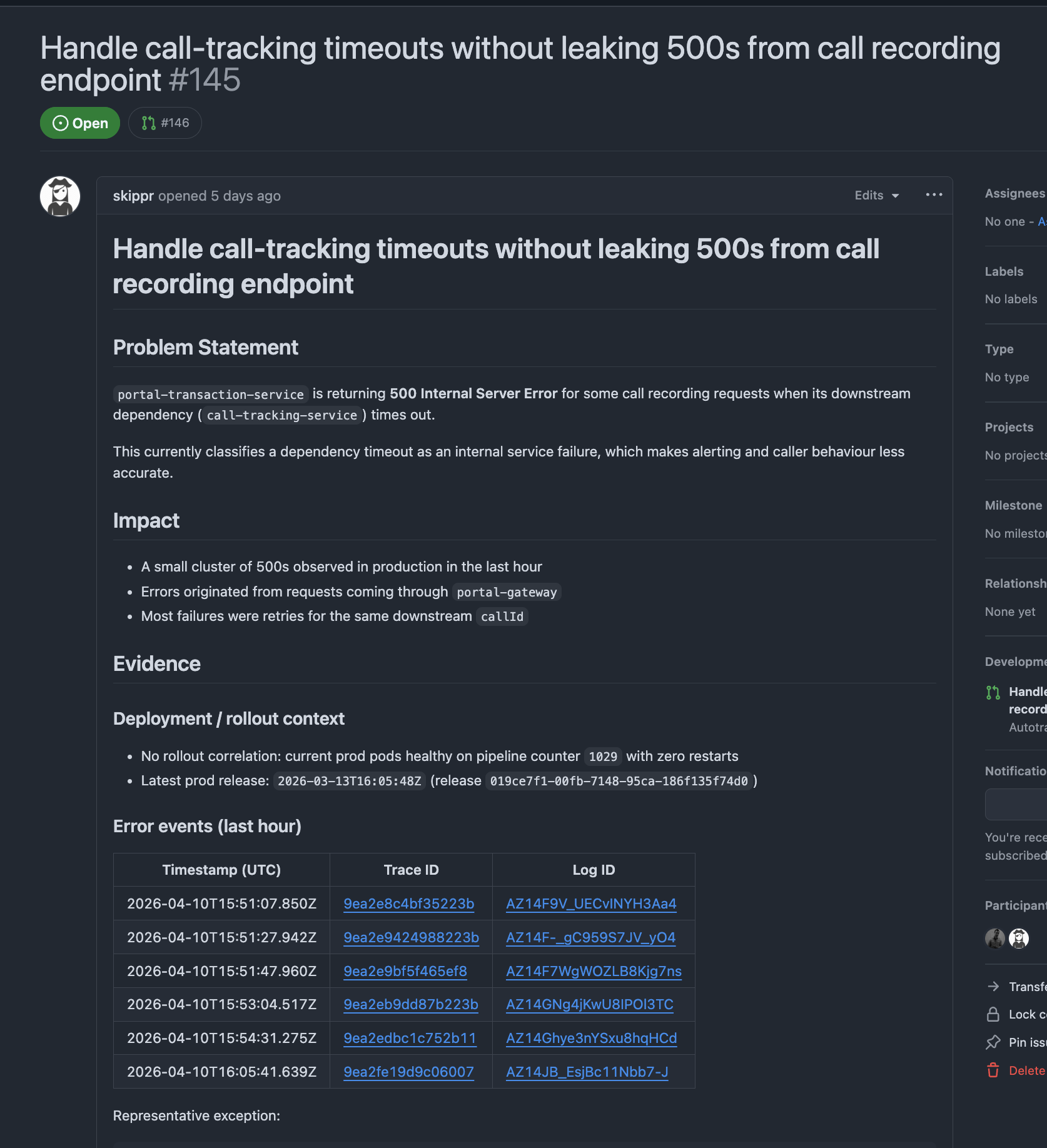
- When a service is deployed, asking
ataito do some manual exploratory testing of it, or perhaps perform a security review using a/pentestskill. - When an incident starts, we can get
ataito do the preliminary investigation and share it into the Slack channel, reducing the Mean Time to Recovery.
The point here is we as a platform team don't need to care. Teams can decide how they want to invoke their agents, and can do so with one API call:
{
"spec": {
"prompt": "my-application is throwing 500 errors in prod, debug them, and then raise a PR for the fix.",
"model": "gpt-5.4",
"agent": "your-agent"
},
"runAt": "a date",
"runEvery": "a cron schedule"
}ATAI Enqueue Event
The schedule aspect is an interesting one, think: "Every Day at 8am check all the services that I own, and give me a summary in slack of their health and areas where I should focus":
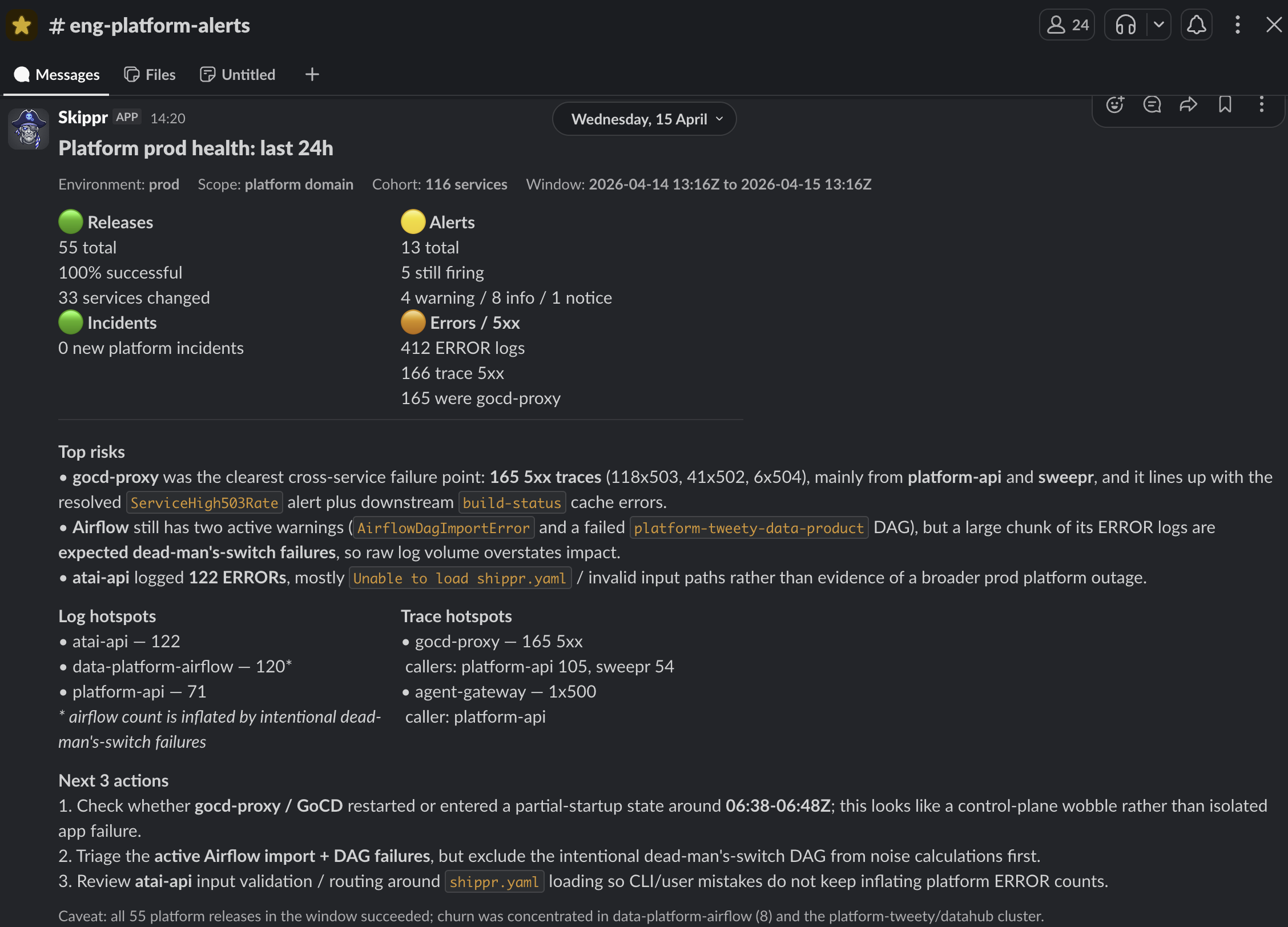
A nod to Platforms
AI is not magic, don't let anyone convince you otherwise. I truly believe one of the key reasons we have been able to move fast with this type of tool is because of the investment we have made in our underlying platforms.
Our Data Platform, and Delivery Platform have completely standardised the way we build, test and deploy software. We have first class APIs which allow us to query information about those systems and get a consistent, accurate, response.
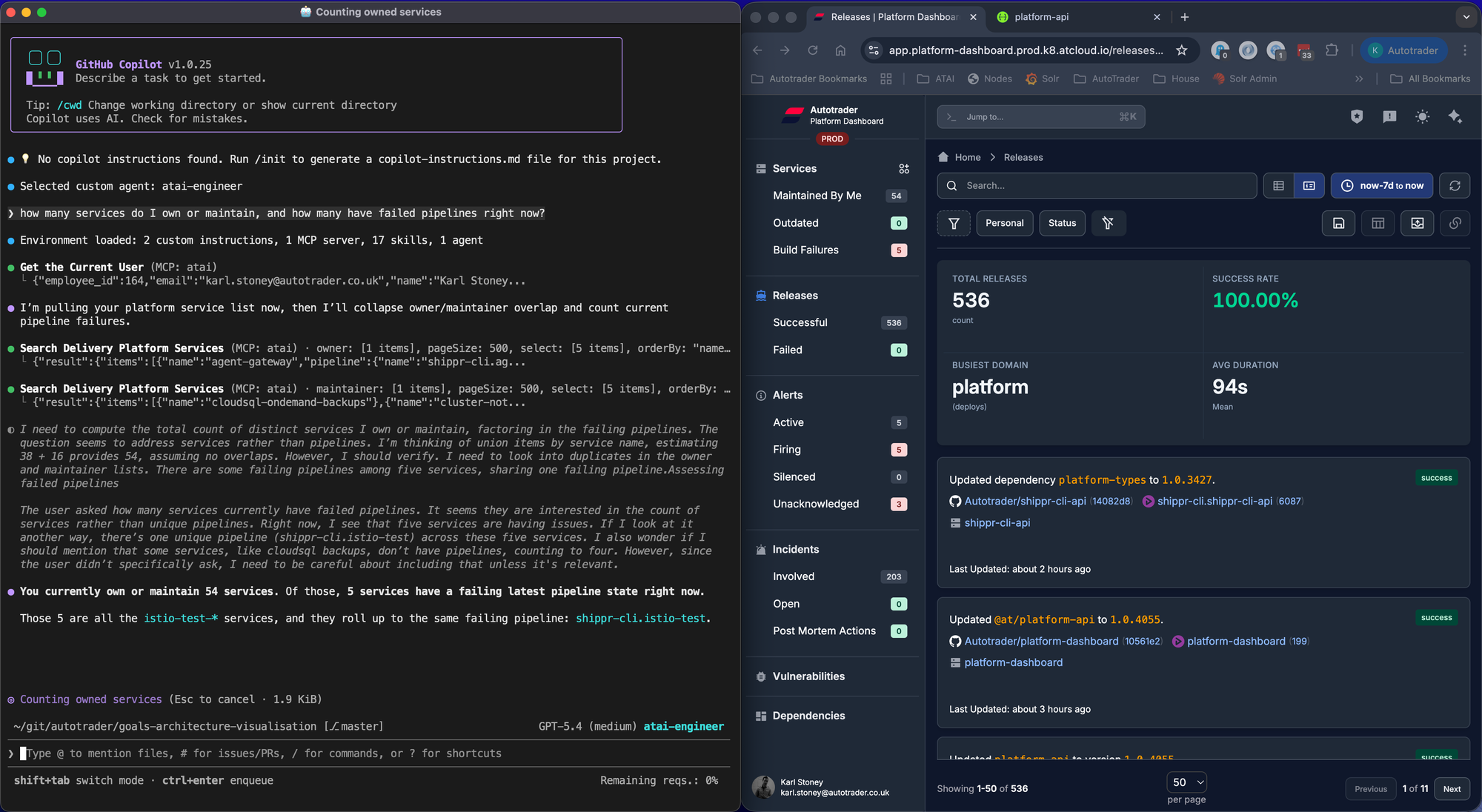
AI doesn't have to guess anything, it's all there, completely deterministic. It doesn't matter if you interact with our platform APIs, the dashboard, or the CLI, the behaviour you get is the same. Like any power tool, AI obeys the law of Garbage In, Garbage Out. Use it to actually clean your house, not just to sweep the rubbish under the rug.
Final take
There is a lot of hype in the industry right now, usually accompanied by wild claims about 10x productivity or replacing entire engineering teams. If you are looking for those kinds of vanity metrics here, you won't find them. We don't measure the value of a tool by trying to calculate a theoretical number of hours saved.
If Skippr does 500 PR reviews a week, you could argue that saves us 250 hours (given ~30mins per PR review). You could also argue that catching bugs before production saves countless hours of reactive debugging. But the reality is more nuanced: engineers still have to validate the AI's work, and occasionally correct its mistakes. If you ship faster, you inevitably introduce new issues, no matter how good your review process.
Fixating on hours saved misses the point entirely. Think about this evolution the same way we think about CI/CD or the Cloud. We didn't adopt cloud infrastructure to necessarily work fewer hours, we did it so we wouldn't have to spend our days racking physical servers. With software, we build standards, libraries, and abstractions to reduce monotony.
AI for me is the next, incredibly powerful extension of that philosophy. It is another tool in our engineering belt, albeit a heavy-duty power tool! It offloads the dull, repetitive tasks and clears space so humans can focus on the high-value, complex problems that actually require their ingenuity.
I believe the real proof of value isn't found in a spreadsheet - it is found in adoption. If this platform wasn't genuinely excellent and making engineers' lives better, they simply wouldn't use it (because we don't force them). The fact that it has become part of our daily workflow is the only metric that matters.