Building an AI Gateway
Building an AI Gateway to centralise common LLM use case cross functional requirements, to accelerate LLM product development.

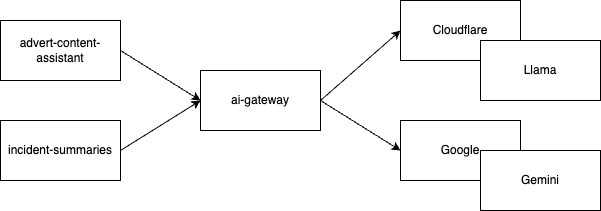
I've been working on a couple of different GenAI use cases at Auto Trader: Incident Summaries, which I've talked about here, and one of our more recently announced features, Advert Text Generation, using our significant amount of data to generate meaningful advert descriptions automatically.
Spiking ideas out with LLM's is very different to building production products. I learnt a lot on that journey, which culminated in building an AI Gateway. AI Gateway is a proxy service to various backend LLMs & Providers that centralises common concerns such as Observability, Circuit Breakers and Fallbacks, Mirroring, Testing, Structured Input, Structured Output, Rate Limiting, Cost Management, and critically allows us to define all those things using Configuration as Code. This allows product teams to focus on building their use case, rather than implementing all of these required components themselves.
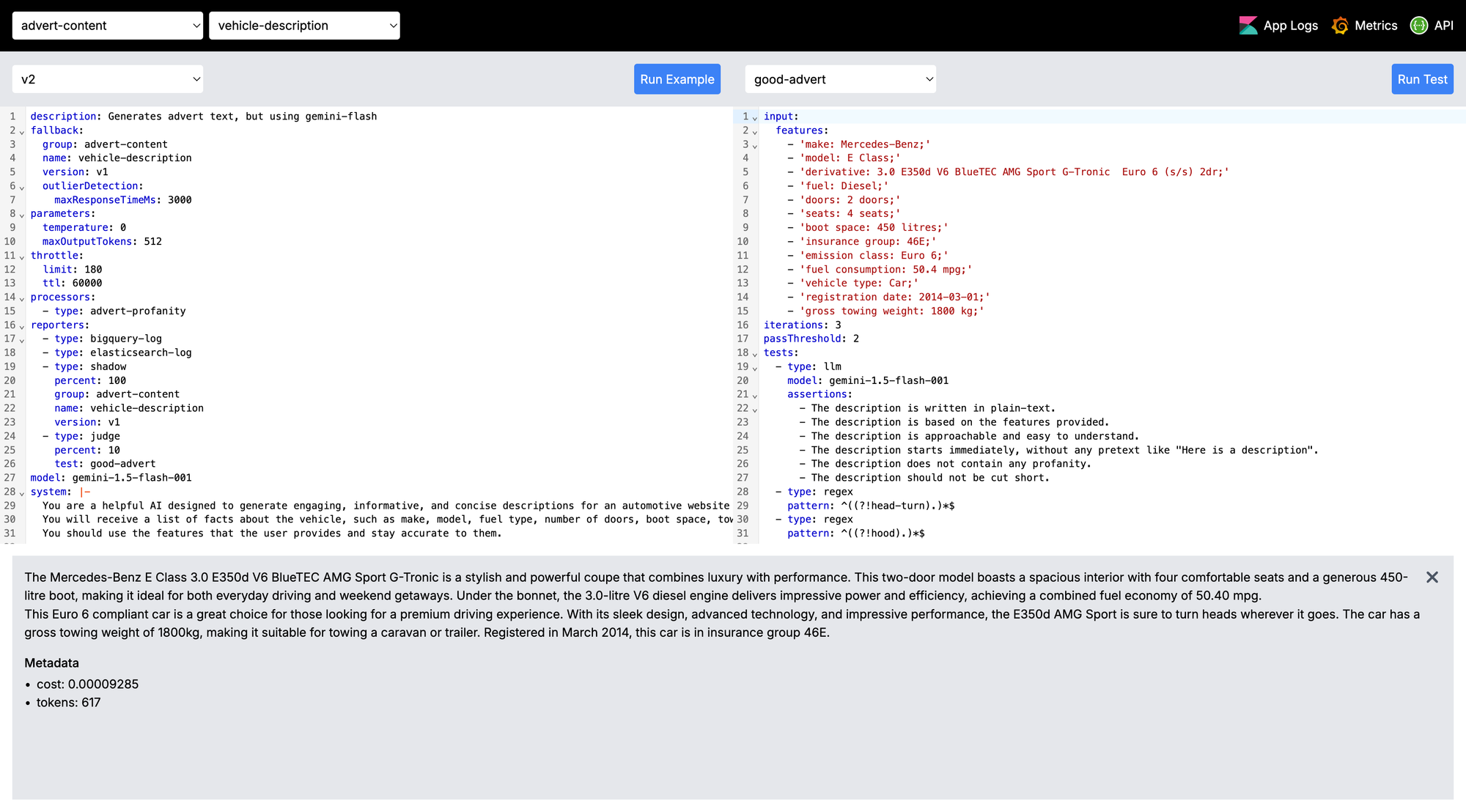
So I'm going to talk a little bit about this app, why some of the features exist - because they're problems you're likely to encounter too. It's worth noting that this post is focused more on the ML Ops side of the fence, rather than the Data Science behind the optimal prompt writing.
Also, here's some terminology to help you as you go through because some terms are pretty overloaded:
Group- Different teams at Auto Trader own different collections of prompts, this allows us to group them together - typically by app name. In the screenshot above, the "Group" isadvert-contentPrompt- This is the individual use case, captured as code. In the screenshot above it isvehicle-description, the configuration for that prompt is on the left hand code editor.Version- All prompts can be versioned, allowing us to test different configurations.Model/LLM- The model, eggemini-flash, orllama-3.18b, etc.Provider- The underlying cloud provider hosting the model, eg Google, or Cloudflare.
It is reasonably long... so grab a coffee before you dig in!
Observability
There is a trend you'll pick up on as you read through this post: "It is absolutely going to break more than you expect". GPU's are in high demand, LLMs are in high demand, and Providers are rapidly iterating over these products. The result: A higher failure rate than you would typically be used to. We've experienced significant waves of significant latency, capacity issues, outright failures, nonsensical responses and so on. As a result AI Gateway exposes common metrics for every "prompt" configuration defined. The types of things we monitor are:
- Total requests by Group, Prompt and Version
- Total requests by LLM (Model) and Provider (eg the Cloud Platform)
- Failure rates (non-200 codes, response time circuit breakers)
- Total Tokens Used & Cost
- & All the standard Golden Signals we capture using Istio
That gets wrapped up into Grafana dashboards automatically, so anyone working on a "prompt" gets dashboard visibility.
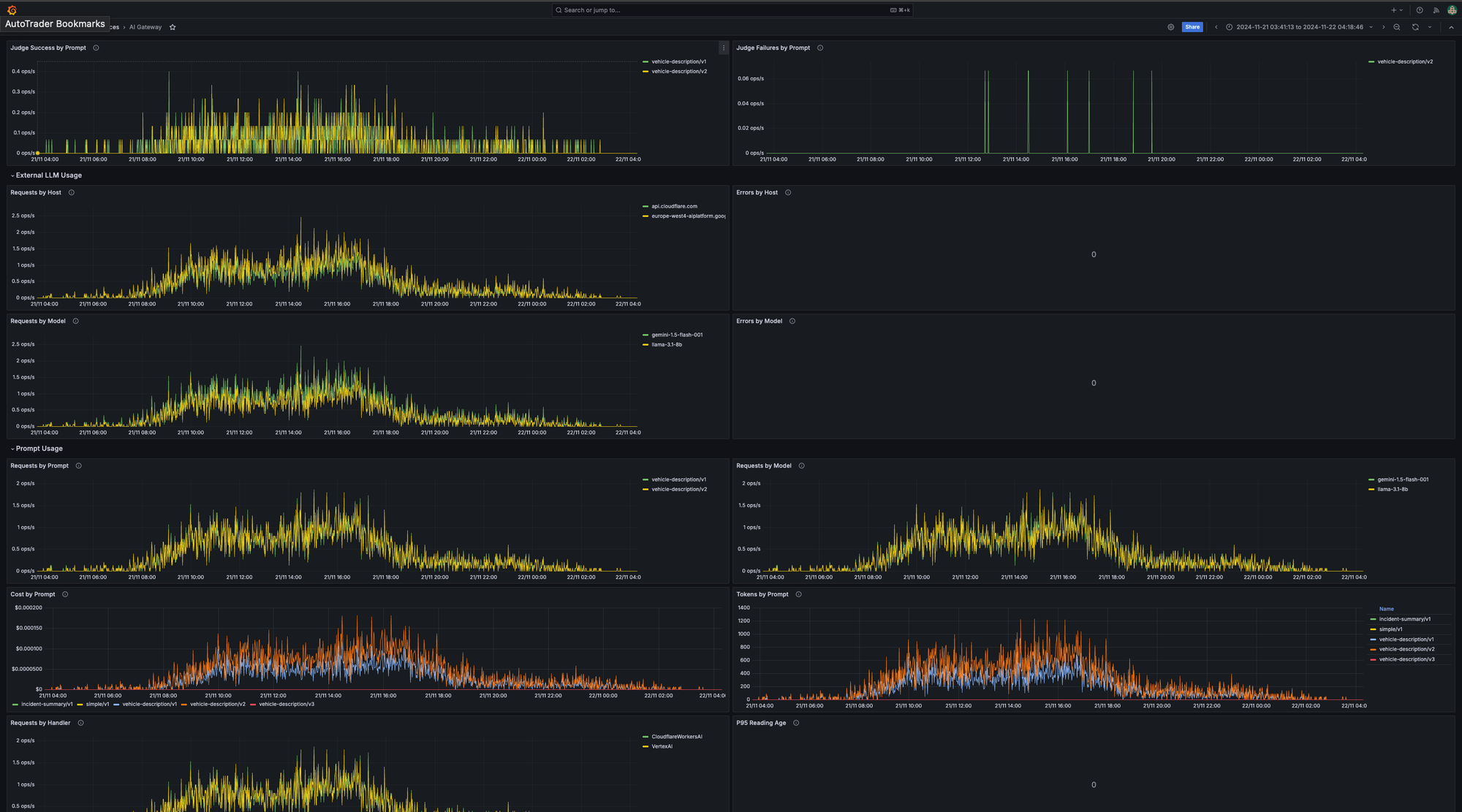
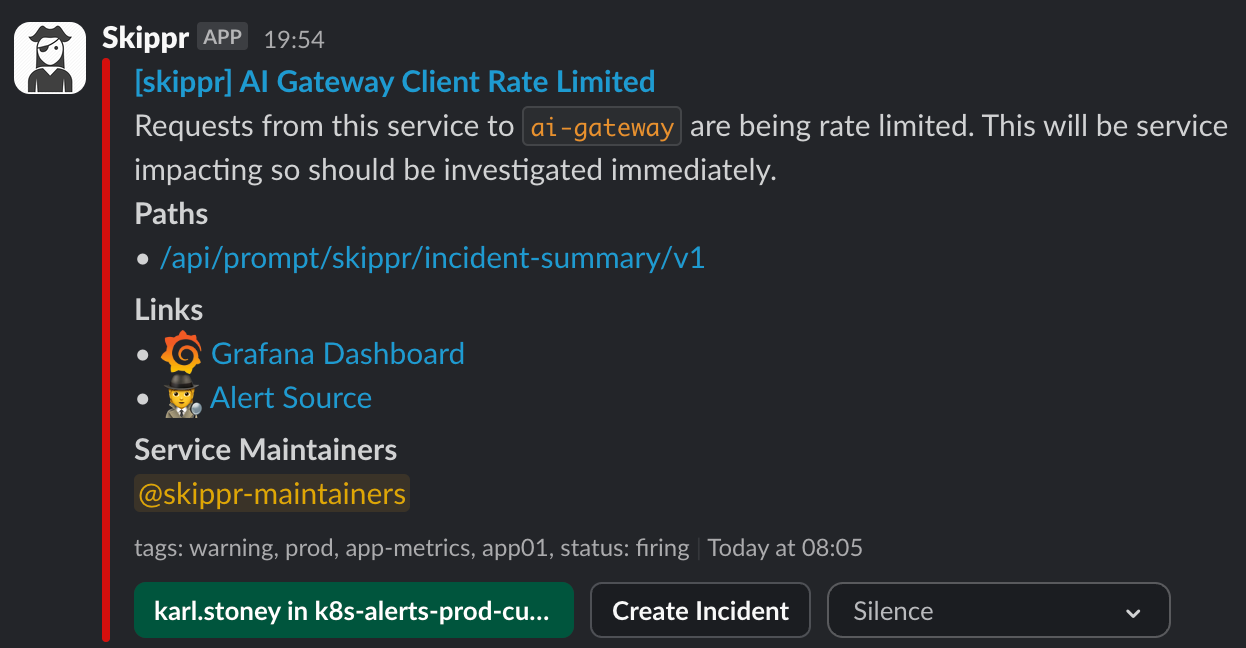
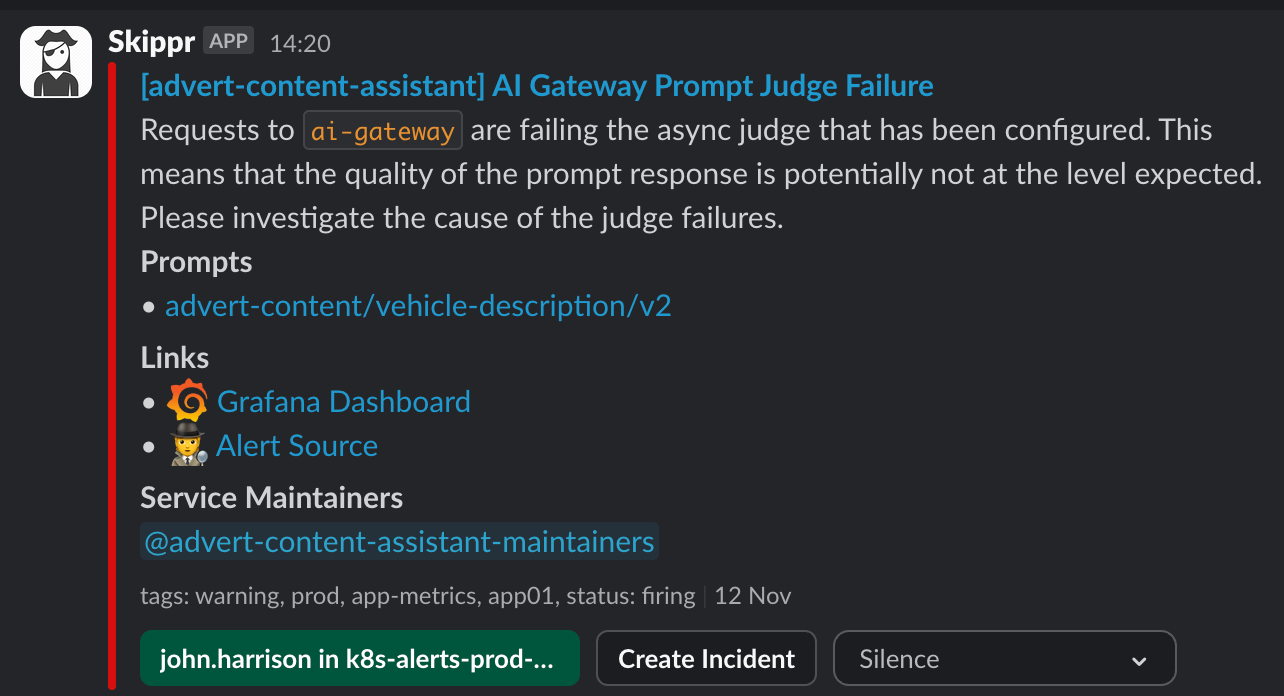
We also automatically generate alerts. AI Gateway is owned by a Platform team at Auto Trader, as a result we want to ensure Prompt alerts go to the right Product team. Because we "Group" alerts typically by the app name, our alerting system is able to enrich the alert by tagging the maintainers of the service, and routing the alert directly to them. Here you can see for skippr - the maintainers have been made aware that their prompt is being rate limited. This pattern ensures that operationally running AI Gateway sits with one team whereas operationally managing the prompts themselves sits with the owning team.
We also allow prompt maintainers to configure reporters, for example:
reporters:
- type: bigquery-log
- type: elasticsearch-log
Reporter Configuration
This configuration would log all prompt inputs, configuration and output to both BigQuery and ElasticSearch. In our use case it allows our Data Science team to build Data Products off the back of the data in BigQuery and our operational teams to use ElasticSearch for real time debugging.
Circuit Breakers and Fallbacks
As a mentioned above - these systems fail a lot more than you're going to be used to. As a result, Prompt owners can configure response time circuit breakers and fallbacks in their prompt configuration, for example in the advert-content/vehicle-description/v1 prompt, we have:
fallback:
group: advert-content
name: vehicle-description
version: v2
outlierDetection:
maxResponseTimeMs: 3_000Fallback Configuration with Outlier Detection
This tells AI Gateway that:
- We're willing to wait up to 3 seconds for the response before failing (or any non-200 status codes)
- And we should fail by running the v2 version of the Prompt instead
Typically you'd want your fallback to be on a different Provider and potentially even using a different model (to mitigate a situation where the whole world is trying to use the same model causing capacity issues everywhere), for example you might have your primary prompt using gemini-flash on Google, but your fallback using llama-3.18b on Cloudflare.
You really need this if you want some decent availability of your system. For example, Google claim 99.9% availability for Gemini, which means ~ 43minutes of unavailability a month. However that policy only covers 5xx codes, you will hit plenty more capacity issues (429) even if your project has sufficient quota, or periods of latency spikes that you're not willing to tolerate. For example, we can't even use flash-002 right now because of the frequent 429's, Google give no clue as to their underlying capacity so you can't even make an informed decision about when to move across, but what we do know is 001 is being deprecated in April so we've got to do it at some point soon. Equally on Cloudflare again we have no view of the underlying capacity, we've been using a small % of our configured limits but still been repeatedly hit by capacity contention issues resulting in significant latency.
It is going to break in the most annoying of ways. Embrace it. My advice here, given the frequency of failures we observe is to just ensure your system seamlessly handles periods of 15-30 minutes of failure. Don't bother alerting anyone to this and just consider it "normal", only alert when your failure state has persisted for longer than that period (or your fallback is down too, obviously). Use that data to have service reviews with your Providers, but don't wake people up on call about it.
Here's a graph of Gemini on Vertex just to demonstrate, response times anywhere between 2s and 16s:
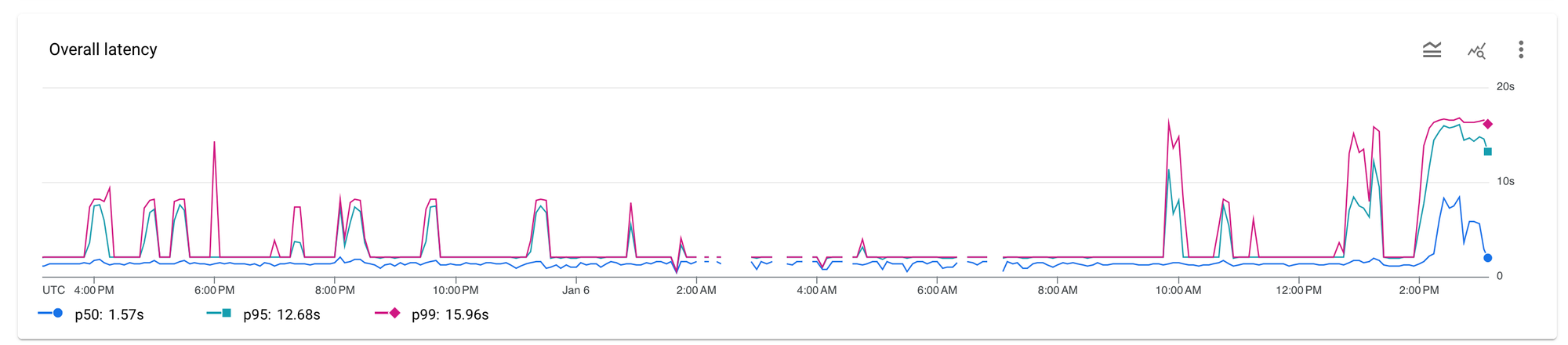
Do remember though that your LLM prompt (and system prompt) are quite closely coupled to your model (and even your provider). Don't expect the same Gemini configuration to work seamlessly with Llama for example, it won't. You'll need to cultivate and manage two sets of working configuration that both achieve a measurable output you're happy with.
Update: Since writing this post, the failure rates of these PAAS offerings is so high that we now support astrategy: parallelparameter on our fallback configuration.
This executes both in parallel, so that the fallback is ready if the primary times out, broadly mitigating the impact to our users.
My advice is, if your use case is big enough, and the OSS models are powerful enough - stick to running the models yourselves on your own GPUs. If you are low volume so want to use PAAS, prepare to spend a good amount of time building for frequent failure.
Mirroring
Lets say you've configured a fallback as described above, it's a different model on a different Provider. How do you have continually confidence in it? Our solution was to have AI gateway mirror traffic. The config file contains configurable reporters, which run after the primary prompt generation but async to the original request.
reporters:
- type: bigquery-log
- type: elasticsearch-log
- type: shadow
percent: 100
group: advert-content
name: vehicle-description
version: v2You can see here for this prompt we've configured bigquery-log, elasticsearch-log and critically, shadow. Here, AI gateway is permanently sending 100% of requests to the shadow prompt too, which in turn will log metrics, and have reporters to send to BigQuery for us to do analysis on, and ElasticSearch, to aid operational debugging.
Another great use case for mirroring is Prompt iteration. Lets say we're building v3 of advert-content-assistant/vehicle-description. Google have just released gemini-flash-002 and we want to observe it in a Production environment because lets face it - the cardinality of inputs in production is what will highlight the gremlins. So we create the v3 version of the prompt, set up shadow, and start immediately collecting all the same observability data without risking the primary prompt. Maybe once we switch to v3, we continue to use v2 as the fallback as it's the "known good".
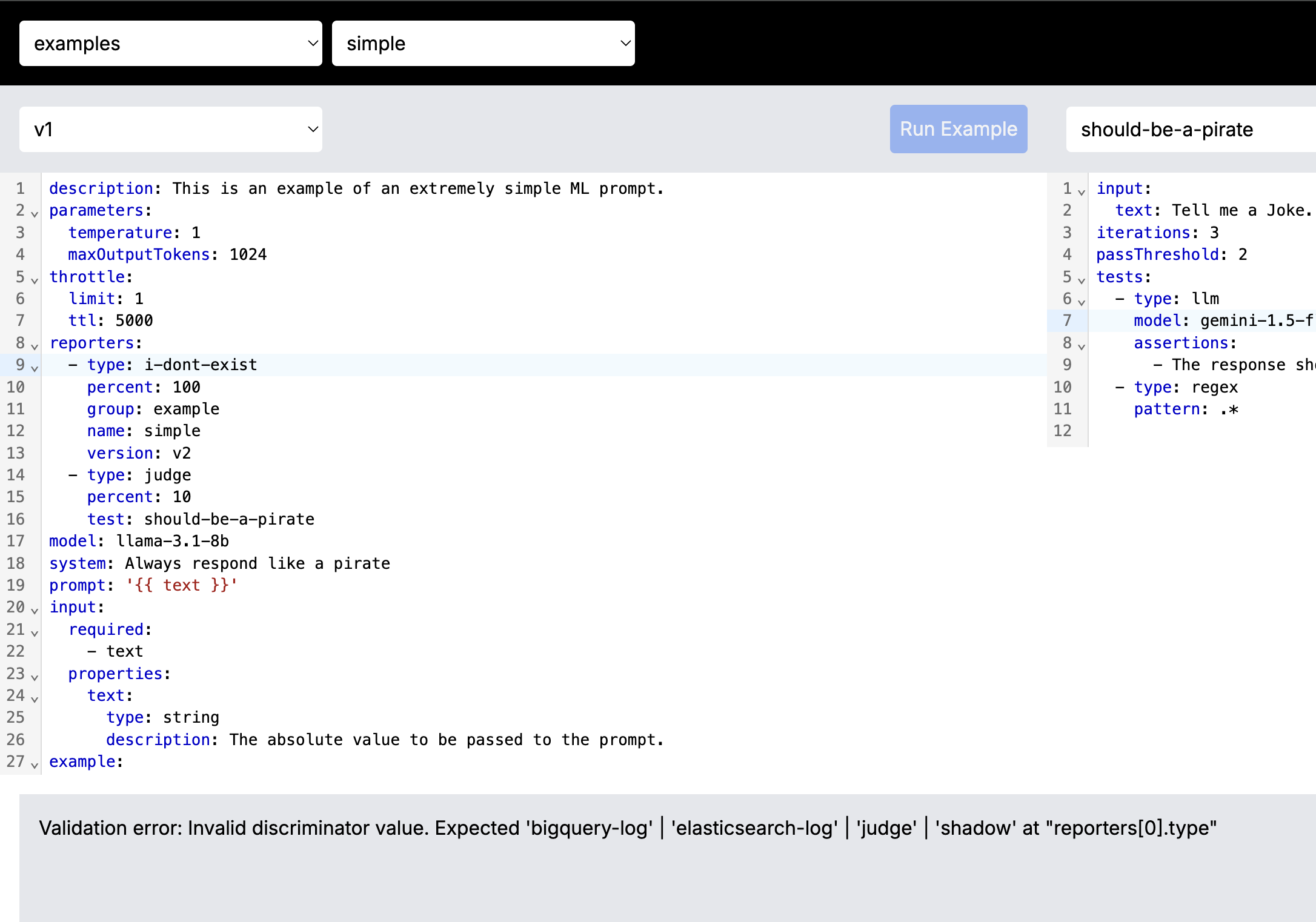
Async LLM Judge
Another way we continually monitor the production environment is with "Judges". A judge is effectively a test that we run some percent of the time and report back in metrics and alerts if it's failing. Take this crude example where we want the bot to always respond in the tone of a pirate. We use llama for the primary Prompt, but then we judge it with gemini.
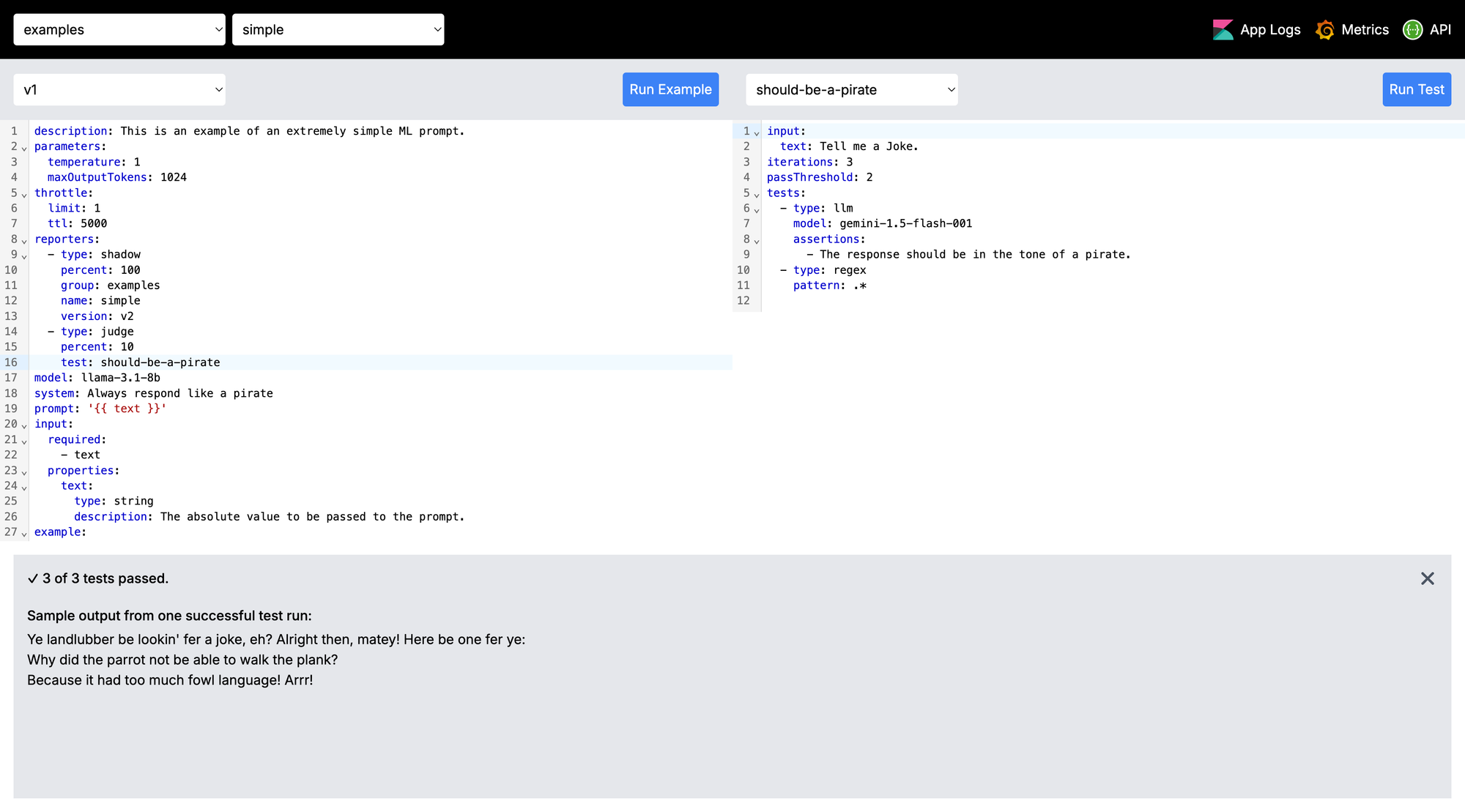
The key configuration here is:
reporters:
- type: judge
percent: 10
test: should-be-a-pirateJudge Reporter Configuration
Tells AI gateway to run the should-be-a-pirate test for 10% of requests.
input:
text: Tell me a Joke.
tests:
- type: llm
model: gemini-1.5-flash-001
assertions:
- The response should be in the tone of a pirate.
- type: regex
pattern: .*
The test configuration; which has two assertions - one to ask gemini if the response was in the tone of a pirate, and another regex test which asserts any output (crude example). As always, our alerting system will tag the appropriate Prompt owners telling them their async judge is failing.
We also run all the judges as part of the deployment pipeline.
Structured Input
Garbage in, Garbage out. Despite what people may think, LLMs aren't some sort of magic sauce where you can just pour it all over some junk input and it'll get glorious output. It might sound glorious, but it rare actually is. A lot of the effort goes into deciding what to give the LLM, be that RAG or even the text input to the prompt.
For example; when generating advert text - it's better to omit a feature (for example - towing weight) if the towing weight is not that impressive when compared to vehicles of a similar class, rather than passing all features and expecting the LLM to pick out noteworthy features. That domain specific logic needs to sit in front. So in that use case it's (very high level), this:
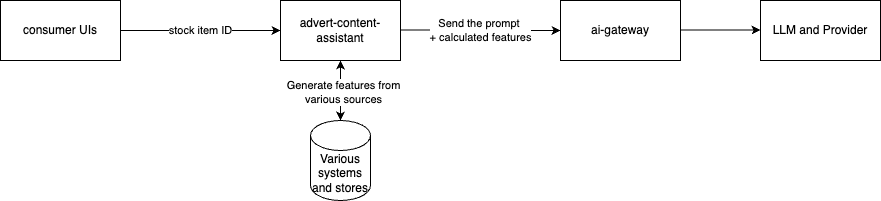
We encourage this behaviour by having Prompt maintainers define structured input to their Prompt, so taking a crude version of advert-text-generation:
system: |-
Your job is to write short descriptions of vehicles, up to about 250 words.
prompt: |-
Write a description for a vehicle with the following features:
{{#each features}}
- {{this}}
{{/each}}
input:
required:
- features
properties:
features:
type: array
description: The features of the vehicle
items:
type: string
description: The feature of the vehicleThe API here will accept an input array of features:
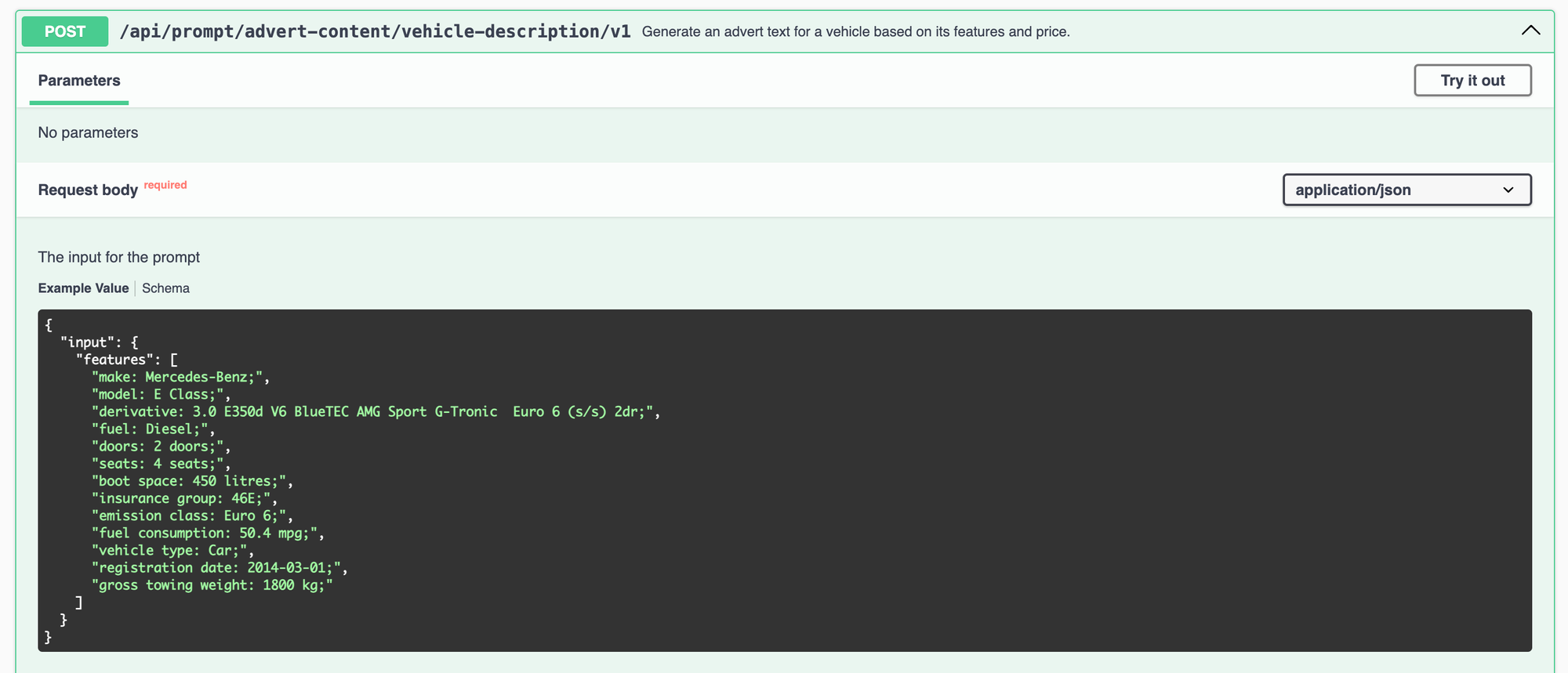
We template those into the prompt in AI Gateway using handlebars. The logic of "what features should we include" lives in a separate service. You will spend more time writing that service than you will working with the LLM for this type of summarisation use case.
It also helps to keep the prompt constrained to a single use case. It's very clear from this API that you can get advert content back, if you pass in a list of features. Anything more generic can end up being shimmed into N different use cases and eventually diluting the effectiveness of the Prompt for a single use case.
Structured Output
Working with LLMs is not a typical software engineering problem space. With the best will in the world, LLMs will occasionally not do what you want, they are non-deterministic word prediction machines.
If you're anything like me, you're used to writing code, secured by tests, that (within reason) guarantee behaviour in given conditions. You're probably used to coding for reasonably well defined failure, eg thinking about HTTP request failures, or network level failures. With LLM's you need to add in the fact that your prompt instructions are not guaranteed. The system will fail more in ways that you would typically anticipate, if you come from a regular software engineering background. For example - imagine having a function called add(num, num) that occasionally multiplies? You get my point.
Lets take an example, getting JSON output. You will likely find yourself in a place where you want structured output, and you may add things to your prompt such as:
Your response must be structured JSON in the following format:
{"message": string}Most of the time, you'll get what you asked for. However occasionally, you might get:
```json
{"message": "the response"}
```Notice how it's just decided to use markdown? Now you can add Never use markdown to your prompt, but it still will - occasionally.
As a result, our consuming systems would always need to contain conditional logic that strips/parses, or outright rejects bad responses and tries again. We decided to push that up into AI Gateway. Users define an output section in their prompt configuration file, such as this:
output:
required:
- detection
- impact
- mitigation
- nextSteps
properties:
detection:
type: string
description: A brief summary of how the problem was detected
impact:
type: string
description: The business impact, both to our teams and customers
mitigation:
type: string
description: Any mitigating steps that were taken in the incident
nextSteps:
type: string
description: The next steps, following mitigationAI Gateway takes that configuration and does a few things. Firstly, if the user has an output section, we append to the prompt the instruction to return JSON, for example:
Your response must exactly be a JSON object which is valid against the following json schema:
JSON.stringify(expectedOutputSchema)
Do not replicate the schema, simply generate an object with the properties defined in it.
The response must be plain text, no markdown or other formatting is allowed, just a JSON object.Most of the time this works, however occasionally, it doesn't. So something else we do is replace markdown, eg we look for "```json" and remove it. Next, we JSON parse the response - this tells us if we even have structured data being returned. And finally, we use a JSON Schema Validator to validate the parsed response against the desired output schema the user specified.
If any of these tests fail, the prompt response is thrown away and we try again (up to 3 times).
Another really nice benefit here is we're able to use the same JSON schema to dynamically build up the API endpoints on AI Gateway. As you can see from the swagger here, the output response is typed as per their configuration. The user is able to hit AI gateway with a HTTP request and get back structured JSON. This makes building programatic API's on top of LLMs pretty trivial.
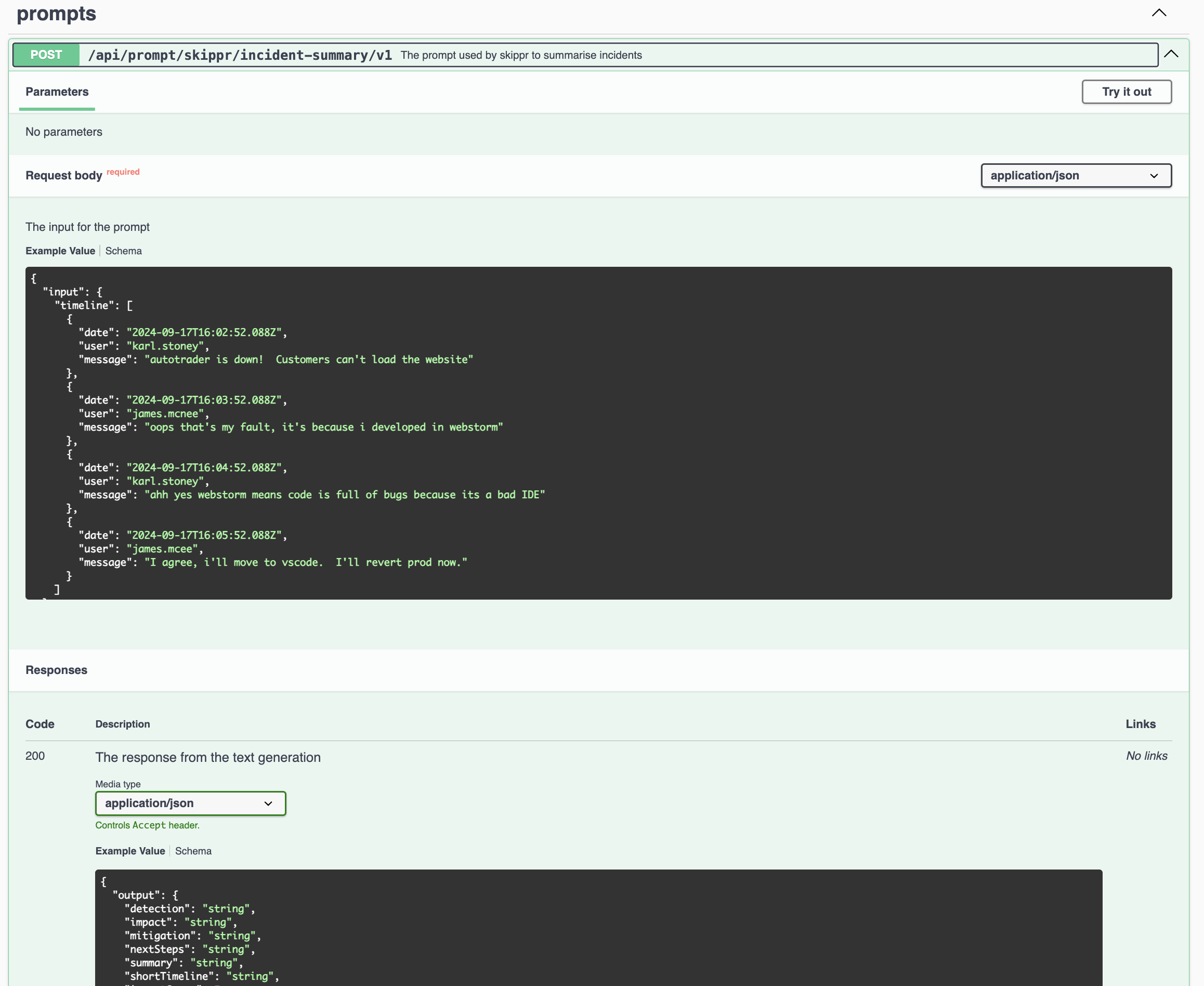
Rate Limiting
One challenge with building a multi Provider gateway is that you have rate limits with your underlying providers, as a result, we need to manage rate limits internally to ensure that one prompt configuration can not cause an underlying provider rate limit - taking out the others.
As a result, on each prompt configuration we mandate that a throttle configuration is set up, for example:
throttle:
limit: 180
ttl: 60000Here we're saying a max of 180 requests in a 60s window. Behind the scenes, we have Provider and model level rate limits with Google and Cloudflare. As a result, we're able to ensure that the needs of our prompt configuration's can be met by the underlying provider rate limits (which can be adjusted) whilst simultaneously ensuring that one prompt, eg incident-summaries can't cause noisy neighbour with another, eg advert-content-assistant.
Cost Management
As we get a high level bill from the Provider, we want to be able to do cost attribution to the underlying Prompt configurations. Some of the challenges in this space are:
- Each Provider reports token usage differently, or not at all. For example Google return the token usage with the response (great), but Cloudflare currently do not (its coming) - which means you have to estimate.
- Each Provider and model bills differently. Some Providers charge the same price for input and output tokens, others charge differently.
As a result, AI Gateway handles this complexity and exports simple cost management information:
ai_gateway_prompt_tokens_sum- the rolling sum of all tokens used, with dimensions forgroup,prompt,version,modelandprovider.ai_gateway_prompt_cost_dollars_sum- the same dimensions as above, but a calculated cost.
The one commonality however is the billing by token usage. As a result, bigger prompts (input) and bigger responses = bigger bills. Same goes for performance, more tokens = slower completions. Subsequently you need to track these metrics, and be able to correlate jumps back to releases of your prompt, which leads us nicely to...
Configuration as Code
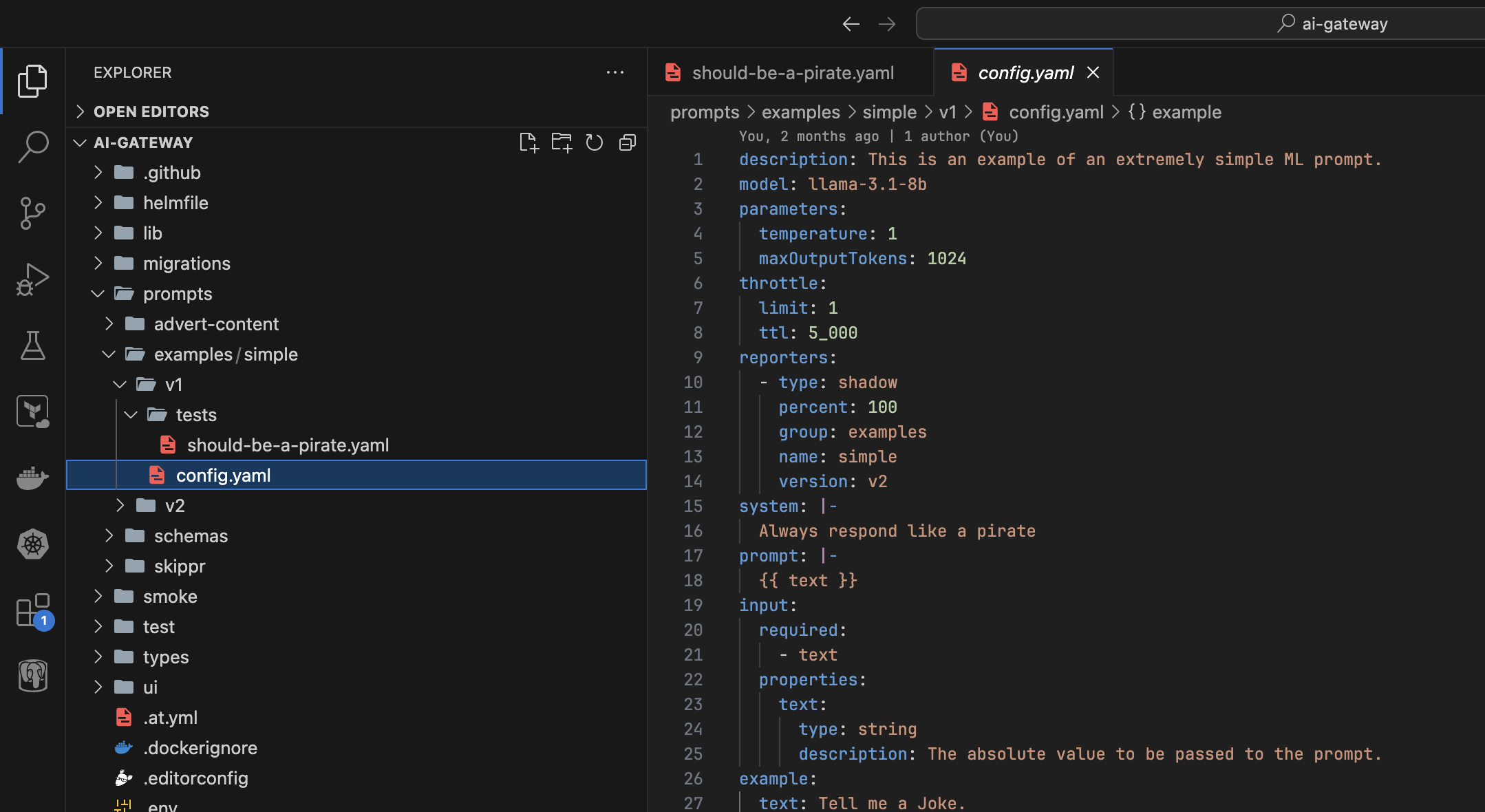
You'll have picked up on this by now but just to reiterate, all configuration for these prompts is checked into Git and deployed via CI through our environments like any other piece of code. All of the Judge tests are run as part of that pipeline too. The UI you've seen in various places is to aid Developer Experience, to allow you to quickly iterate over prompt:
Critically, there's no save button. Changes are expected to be committed back into git and deployed via CI:
Authentication
Each of these LLM Providers has their own models for authentication. We have 100's of developers, we aren't going to distribute API keys for Cloudflare to them all, nor are we going to set them all up with access to Vertex on Gemini.
We have a standard capacity called "Platform Oauth" here, any deployed service can utilise it by setting oauth.enabled: true in their application deployment configuration. This will put a transparent proxy in front of their application and subsequently hand off authentication to our Employee IDP (Azure). AI Gateway handles the authentication to the backend LLM provider. This means that developers can use AI Gateway using their employee credentials, not needing the underlying provider credentials in each application, or with each developer.
It's this tight coupling to our private systems that means we didn't use tools like Cloudflares AI Gateway. The best developer experience here was delivered by building it ourselves.
Conclusion
Hopefully you can see - quite a lot goes into using an LLM in production. Pulling all those concerns together into a singular gateway means that product teams are able to focus on the product they're building (eg incident summaries, or advert text generation), rather than all the nuances of operationally working with LLMs.
curl -X 'POST' \
'https://our-gateway/api/prompt/examples/simple/v1' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"input": {
"text": "Don'\''t you just love AI Gateways?"
}
}'
{
"output": "Yer love fer AI Gateways, eh? Alright then, matey! Aye, I be thinkin' they be a fine addition to any swashbucklin' crew's arsenal o' tools! Savvy? They help us navigate the Digital Seas, connectin' us to all sorts o' treasure... er, I mean, all sorts o' data and applications. And they keep our ships... er, systems... safe from scurvy scallywags tryin' to hack us! So, aye, I be admirin' AI Gateways, too!",
"metadata": {
"cost": 0.00001875,
"tokens": 125
}
}
Obviously what we've primarily focused on here is single turn text generation. Our AI gateway also exposes common endpoints for conversations, text-embeddings, image-recognition and translation, as many of the concerns are broadly the same.
The AI Gateway pattern starts to break down however when you start using more Platform or Model nuanced features (eg not common), for example - function calling, or multi modal vary greatly and in my opinion probably shouldn't be abstracted. Those types of use cases are better being built strongly coupled to an individual Provider and Model and accepting you'll still need to implement much of the above.