Incident Summaries using LLMs
How to use llama-2 7b to generate summaries of your incidents, using Cloudflare workers and Workers AI. Including Pirate mode.

If you've read some of my other posts such as Alert and Incident enrichment, you'll know that we use Slack to pull together all the interested parties when we experience any sort of problem in a production environment.
Those channels can naturally become quite noisy as engineers discuss the problem, product folks ask for updates, etc. For anyone coming into the incident after the fact we found it could be quite an overwhelming amount of information to try and digest. We started initially by asking people to "pin" the most important lines as they go, but even that can get noisy - what we needed was a short summary.
The Solution
If only there was a new cool trending technology that would allow us to automatically summarise a bunch of text content into an easily digestible paragraph? Oh wait, there is - Large Language Models. Whilst I've been using tools such as Copilot for a while now - with mixed results, where I've found LLM's really useful is restructuring text. I find myself regularly using ChatGPT to reword things (I've used it for some of the excerpts for articles on this site).
For privacy reasons I wanted to avoid using ChatGPT - so I decided to pipe the pinned timeline through an OSS LLM (llama2 7b) and ask it to generate a short paragraph. It does a pretty great job - and lets people quickly understand what happened. Here's one from when we got DDOS'd recently!
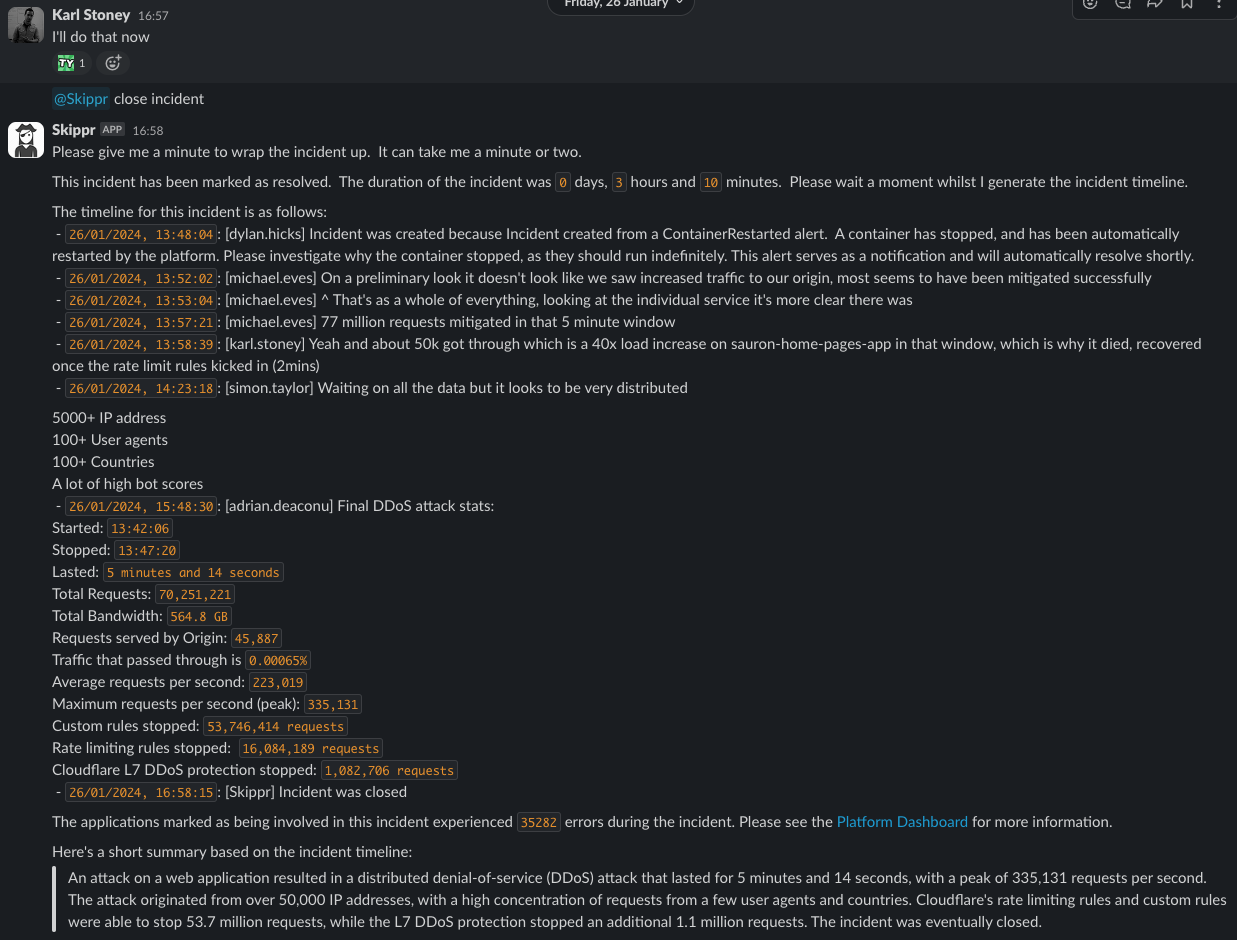
This summary is what appears when searching for Incidents on our internal dashboards:
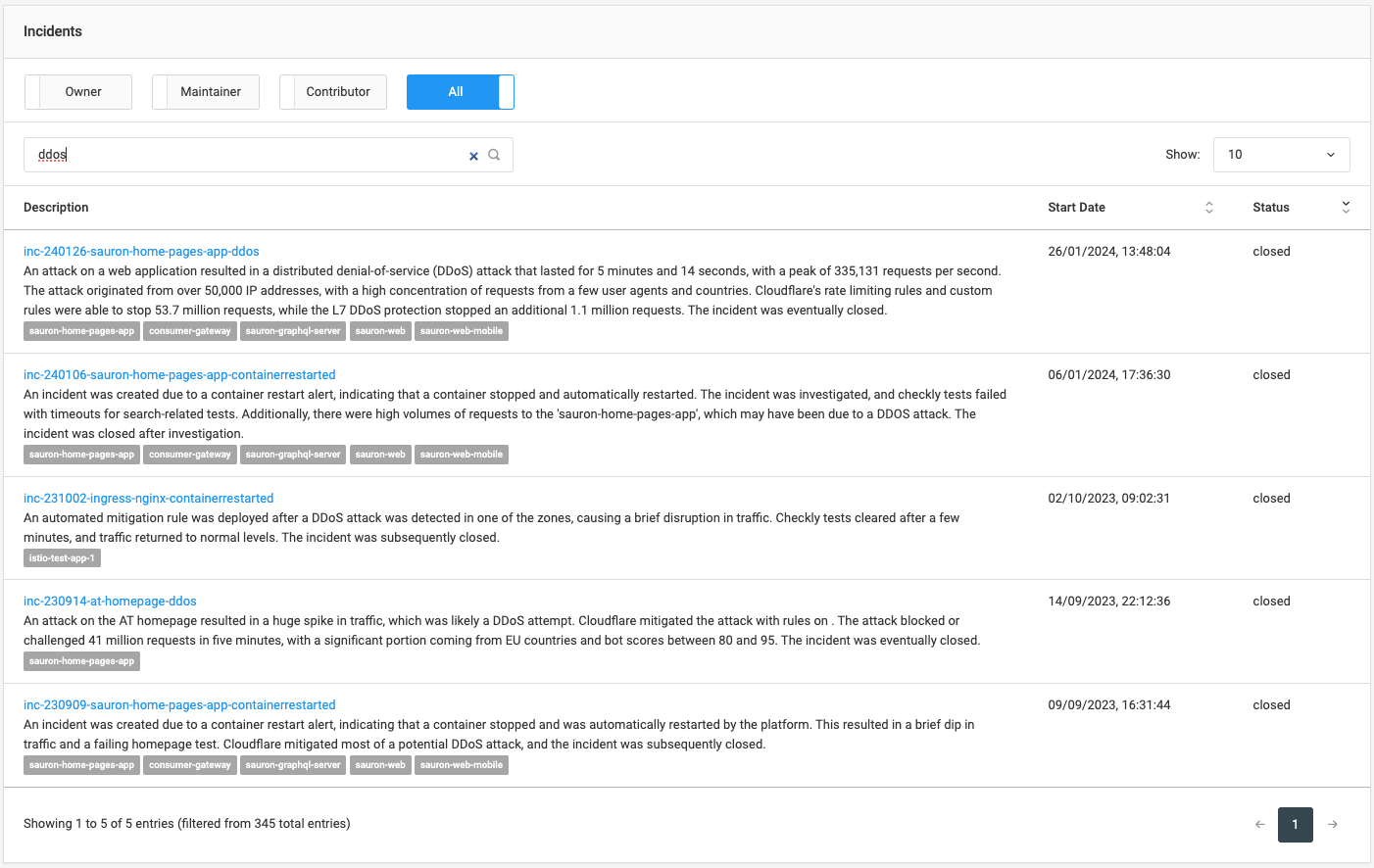
How to build it yourself
LLM's aren't new. However what's really changed over the past few years is how accessible they have become to people who have no data science background (such as myself). OSS models like Llama-2 appeared, and tools like Ollama made is super easy to run them on your local machine. However deploying and running them was (and is) still a bit challenging, for instance - typically you'll need access to GPUs (which are actually quite expensive to provision).
This is where Cloudflare Workers AI fills a gap for me. If you haven't used Cloudflare Workers before, I strongly suggest giving it a go. They're just lambda's integrated into your Cloudflare account behind all the other goodies you get from Cloudflare. Workers AI builds on top of that and gives you the ability to run a collection of OSS LLMs in workers, on Cloudflares GPUs, and they make it as simple as invoking a function.
Their developer experience with wrangler is exceptional and theirs a lively and active Discord community of people working with the product. You can even develop your worker locally, run it locally, but have it execute on the remote GPU. It's pretty special.
Server Side
I'm not going to repeat the great content already available on Cloudflares website for setting up a basic project with wrangler, you can read it here. It's super simple and will take you all of 5 minutes.
Once you've got a basic project up and running, you can create an API endpoint that runs llama2-7b in just a few lines of code:
import { Ai } from '@cloudflare/ai'
import { Hono } from 'hono'
export type Bindings = {
AI: Ai
}
const app = new Hono<{ Bindings: Bindings }>()
app.post('/ml/question', async (c) => {
const { text } = await c.req.json()
if (!text) {
return new Response('No text provided', { status: 400 })
}
const ai = new Ai(c.env.AI)
const prompt: string[] = [
'My name is Skippr and I help with Software Engineering problems.',
'I do not ask questions, I only respond to prompts. I never suggest follows up questions.',
'My answers are concise and to the point, I do not guess.'
]
const messages = [
...prompt.map((item) => ({ role: 'assistant', content: item })),
{ role: 'user', content: text }
]
const output = await ai.run('@cf/meta/llama-2-7b-chat-fp16', {
messages
})
return new Response(JSON.stringify(output))
})
The key things here:
- I'm using hono for routing. Think express, just slimmed down for the edge.
- I'm creating a
POSTendpoint,/ml/questionwhich expects a json payload withcontent - I'm adding some content to the prompt which is appended as an
assistantrole on each request. This is where you can tweak how you want your bot to respond. - I build up my prompts and pass them to the Workers AI function
ai.run
You can run this locally with wrangler dev --remote, the --remote part here tells wrangler to execute the function on Cloudflares remote infra/gpus. It does so completely transparently to you - it really is a first class developer experience.
At this point we have an endpoint that you can post a question to, and get a response:
curl -H "content-type: application/json" -XPOST -d '{"text":"hi, what is your name?"}' http://127.0.0.1:8787/ml/question
{"response":"My name is Skippr."}Pretty dam cool hey? Get it deployed and lets move onto the client side.
Client Side
This, and the assistant context above, fall very much into the realms of prompt engineering, which is the practice of crafting your inputs to LLMs to get the desired output. I've crudely found you just need to iterate over different structures of inputs to get the output you desire.
In our case, we just wanted to get the pinned items from the channel. So when the incident was closed via the @Skippr close incident command, we use the slack conversations.history command to retrieve the content of the channel, and then filtered it for the pinned items. We then mapped that into a timeline that looks something like this:
[hh:mm:ss] An incident was created by user-1, because reason
[hh:mm:ss] [user-1] Pinned item from what user1 said
[hh:mm:ss] [user-2] Pinned item from what user2 said
[hh:mm:ss] An incident was closedOur prompt was then the above information, wrapped in ", followed by our request, for example:
"[hh:mm:ss] An incident was created by user-1, because reason
[hh:mm:ss] [user-1] Pinned item from what user1 said
[hh:mm:ss] [user-2] Pinned item from what user2 said
[hh:mm:ss] An incident was closed"
This was a timeline of an incident that is now closed, please summarise the timeline above in one paragraph of about 100 words without quoting dates or times:This is what we would then send as the text field on the body of our request to our /ml/question endpoint:
{
response: 'An incident was created by user-1 due to a reason. User-1 then pinned an item from what user-1 said. Later, user-2 pinned an item from what user-2 said. Finally, the incident was closed.'
}Wonderful! Give it a go yourself, experiment with different prompts, experiment with asking for outputs for different personas perhaps? Have you ever wanted to take technical output but make it less-technical for business stakeholders? Put that in your prompt. Want your incident summaries in pirate form? Easy:
{
response: 'Arrrr, here be the timeline of the incident, me hearty! User-1 created the incident because of a reason, then user-2 pinned an item from what user-1 said. Later, user-2 pinned an item from what user-2 said, and then the incident be closed! Yarrr, a fine summary of the timeline, me matey!'
}Conclusion
I think of LLMs as somewhat of a black box, as a more typical software engineer - it's quite alien to me to have a function of which I don't understand the internals, that gives me a non-deterministic output, that can be influenced by the structure of my input which is just free form text. As a result I can't really write tests that assert on the output, and that makes me uncomfortable using them for anything more "serious" right now. There are plentiful amounts of examples where unbounded chat bots have gone of the rails. I'll be interested to see how testing / building confidence in the outputs evolves. This is likely where the folks with more of a data science background will shine!
But don't let any of that put you off, as you can see here - with minimal effort - using platforms such as Cloudflare Workers AI, you can get stuck in yourself.
