Upgrading Istio to 1.7
Upgrade from 1.6 to 1.7 was less effort, but caused more impact than previous releases. Memory usage jumped again, but there's light at the end of the tunnel.

It's only been 3 weeks since we made the move from 1.5 to 1.6. But seeing as Istio version 1.8 was just released - which subsequently means support for 1.6 has now ended - we decided to keep up the momentum and crack on with 1.7 as well.
It was anticipated that the 1.7 migration would be notably less painful than 1.5 and 1.6, and whilst overall that was true, it was less effort to get it deployed, this was the first time we have encountered, in production, traffic impacting issues that were not picked up in our qualifying environments. More details further down.
Increased memory footprint (again)
If you read my previous post talking about the 1.6 migration, you will be aware that we experienced around about a 15% increase in istio-proxy memory footprint. Unfortunately this trend has continued with 1.7. Initially we saw another 20-25% increase in data plane memory usage. With the average base footprint of a proxy (without configuration) going from 40mb to 50mb
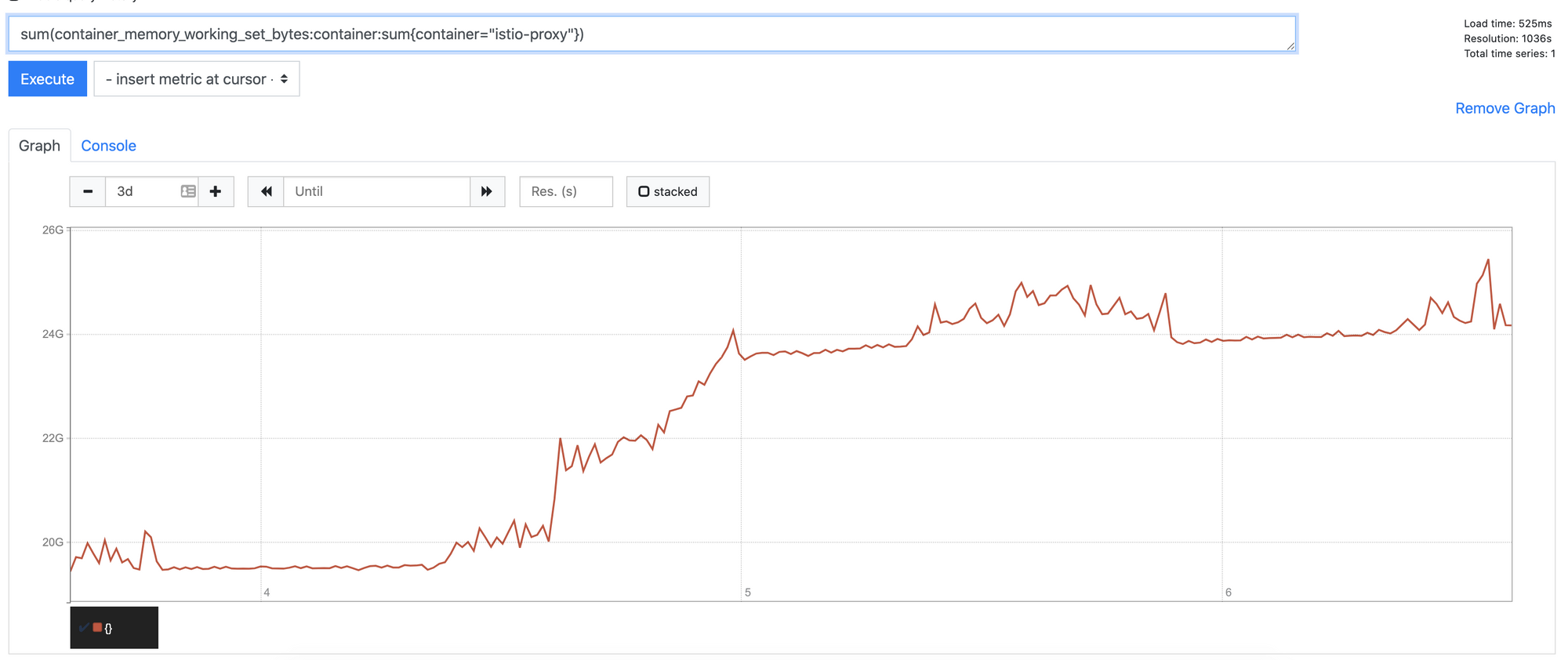
This is a known issue, and numerous fixes are being tracked in this Github issue. Fortunately John at Google back ported some of the improvements that were in 1.8 to 1.7, closing the gap quite significantly. The changes released in 1.7.5 have lowered the increase to around about 5% cluster wide.
The good news is that in 1.8 (and master/1.9), memory usage is below pre-1.6 levels, so this should be some short term pain.
Guaranteed issues during upgrades from 1.6
I cannot stress this enough:
Do not upgrade from1.6to anything other than1.7.5
I mean it, don't. There are a few issues that will hurt you:
TLS Version switch causes momentary, cluster wide traffic faults
The details are in this issue but the crux of the matter is, a switch in TLS versions will cause cluster wide impact until all proxies have reconciled with the 1.7 control plane. This is fixed in 1.7.5.
Transfer encoding changes break 204 response codes
Details are here - at a high level, if you have a source service on a 1.6 proxy and a destination service on a 1.7 proxy - and the destination service returns a 204 response it will fail with a 503. Again, fixed in 1.7.5.
503NR during rollout of control plane
Frustratingly - we experienced a host of 503NR codes on high throughput services (those doing 500+ ops/sec) during the control plane upgrade seemingly whilst all the 1.6 proxies reconciled to the 1.7 control plane.
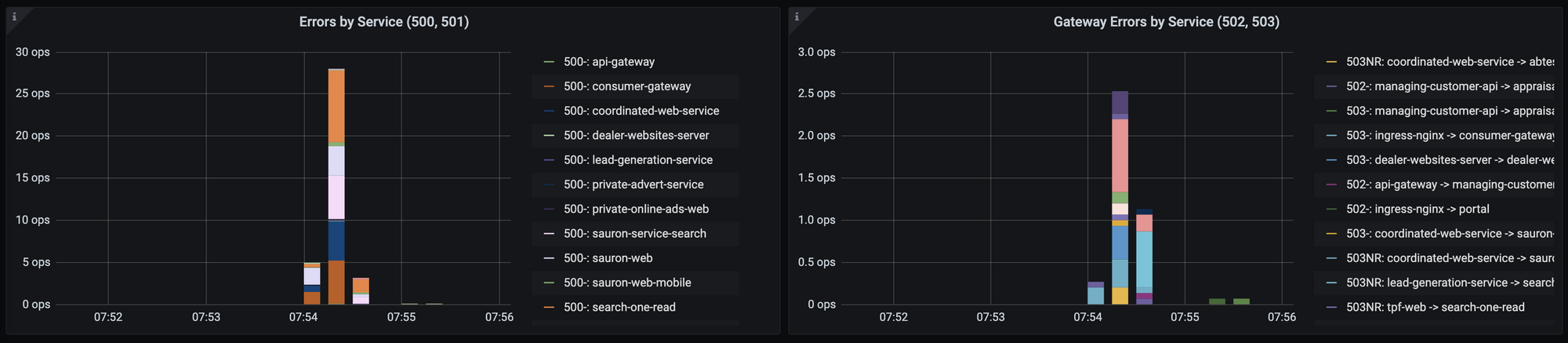
We tested going back and forth between 1.6 and 1.7 under load numerous times in non-production environments, so as it stands I am unsure what caused this.
I believe if you do canary control plane rather than in-place control plane upgrades, you shouldn't hit this issue. If, like me, you do in-place control plane upgrades - be prepared for the above.
Summary
There were no fundamental changes that required significant amounts of rework, purely request based / environmental gotchas. However the 503NR's we experienced were frustrating - especially seeing as we haven't been able to consistently recreate them to debug the issue further.
I cannot stress enough the importance of good qualification environments that are as identical to your production as possible. Something I also do is have a test suite of apps constantly creating varied traffic (all sorts of status codes, http methods etc) continually running, to help detect any left field issues as soon as possible. I shared some of my code on Github to give inspiration for how I do this at AT.