Locality Aware Routing
Talking through the Pros and Cons of the default-enabled Locality Aware Routing on Istio and the steps you can take to make it work for you.

I've recently discovered that Locality Aware Routing is enabled by default on Istio. To make it even more confusing it actually only starts doing anything if you also configure a different feature - outlierDetection, so for most users I feel this will end up getting enabled as a side effect.
I was needless to say a little bit surprised by the decision as there are lots of quirks to think about when this feature is enabled.
In case you don't want to read the whole thing, here's my top level summary:
Turn it off. Then selectively turn it on per-service where the benefits outweigh the complexity, and carefully monitor the impact on your golden signals
Pros and Cons
There are no golden bullet features. Yes, Locality Aware Routing can:
- Slightly improve latency due by keep traffic in the same locality
- Reduce your cross-zone data transfer charges if you're in Public Cloud (We saved $30k/year by enabling it on a handful of services)
- Reduce the impact of issues within a single zone
But there are a few cons:
- Locality is binary, not preferred, in the sense that traffic will go to the same locality, unless that locality is completely unavailable.
- Load Balancing is more complex. It is easy to overload instances of an application within a given zone.
Uneven Zonal Distribution during Deployments
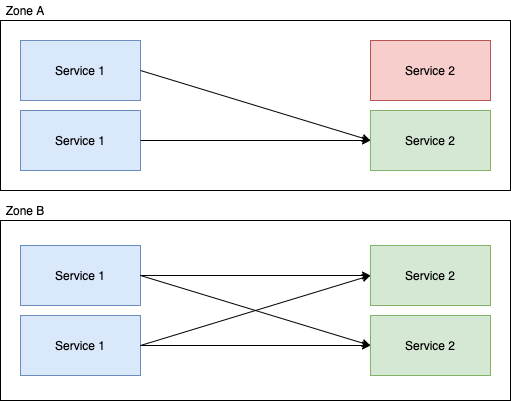
Lets take a really simple, two locality two service setup where we assume the weighting of all requests (in terms of their complexity for service-2) are the same, with the default round-robin request behaviour:
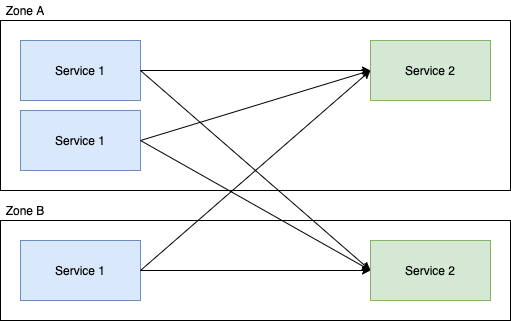
In this example; the downstream calls from service 1 are evenly distributed to service 2 in that each instance of service 2 is going to get roughly 50% of the requests. Now if we enable Locality Aware Routing for this service, we get:
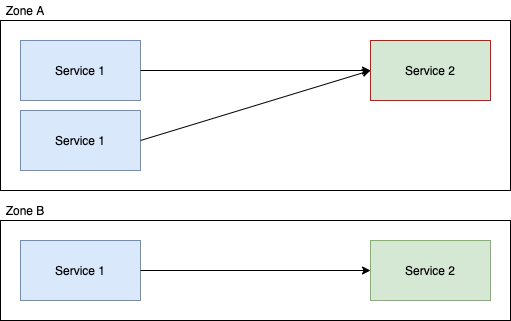
And suddenly you've got ~66% of the load going to one instance of service 2 and ~33% to the other. An extremely imbalanced distribution of load which could easily negate the benefits of the feature.
So how can we fix it?
Ensure that all services in the locality enable service chain have an even number of replicas per locality
Sounds simple really? Just make sure that service 1 and service 2 have replicas divisible by the number of zones, but forced into different localities, like this:
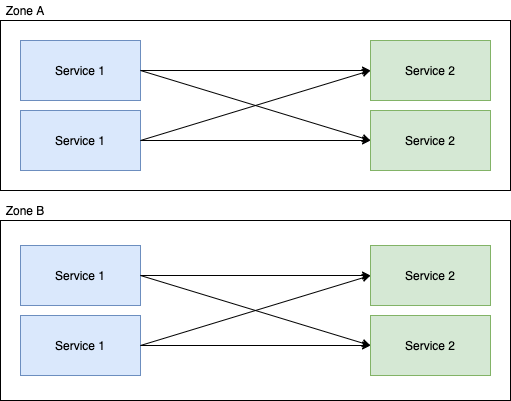
But now we're running 8 instances, rather than 5, there are questions that need to be answered before you can do this, such as:
- Are we OK with the increased cost of running more replicas? Does that negate some of the money we're going to save from cross-zone egress? Perhaps we go down to 2 replicas instead (1 per zone?).
- We're running more instance of
service-1now, was there a reason we only ran 3? Perhaps it was consuming from a message queue and we used 3 to manage the concurrency, does 4 change that profile and what does that mean forservice-2?
Assuming you're OK with changing the deployment profile of these apps, let's look at how we can actually make it happen.
Forcing Replica Numbers
You need to ensure that the number of replicas is divisible by the number of zones. We personally do this in CI/CD with pre-deploy validation scripts, and fail the build with a message letting the developer know why we need an even distribution of pods. Our admin UI constrains run-time scaling in the same way:
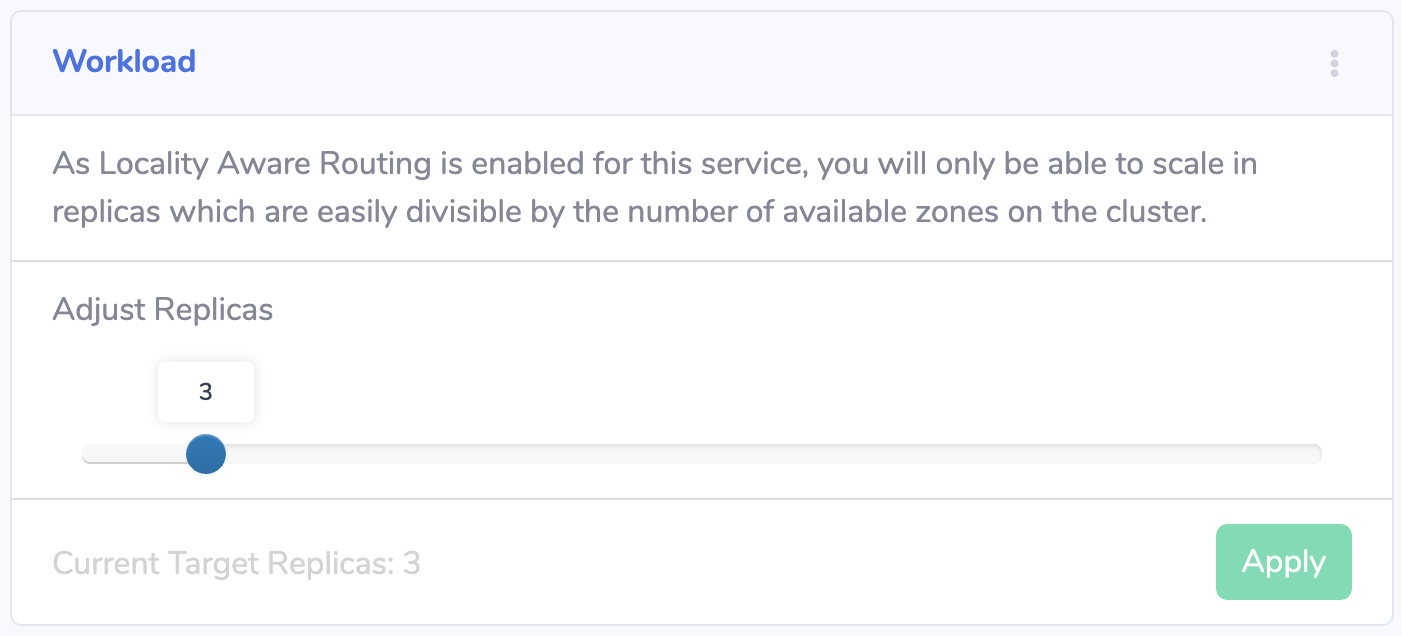
Once you've got the number of replicas correct, you need to ensure that Kubernetes schedules them in a distributed way.
Required Zonal Anti Affinity
You can instruct Kubernetes to schedule your pods into different localities, and this works fine so long as your replicas are <= the number of zones. Taking our example and assuming we have replicas: 2 for each service, and a cluster with 2 localities, we could set:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchLabels:
app: service-1
version: 1
namespaces:
- service-1
topologyKey: failure-domain.beta.kubernetes.io/zoneHowever, if you have replicas > number of zones (say, replicas: 4), the above rule would cause your two additional pods to be stuck in a Pending state, as there are no localities available that satisfy the constraint. Not good, so how do we handle that scenario?
Preferred Zonal Anti Affinity
To support a scenario where the number of replicas > the number of localities, another option would be to switched to a "preferred" antiAffinity rule, which would look like this:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- podAffinityTerm:
labelSelector:
matchLabels:
app: service-1
version: 1
namespaces:
- service-1
topologyKey: failure-domain.beta.kubernetes.io/zone
weight: 100This tells Kubernetes to ideally balance the pods across zones, but the key word here is "preferred". Kubernetes will not autoscale nodes in a locality to satisfy these constraints, it will simply scheduled them in an imbalanced fashion. Leaving you with the imbalanced load we're trying to avoid.
In either scenario, it's extremely important that you have a version label which is unique to each deployment, otherwise your affinity rules will consider pods from different deployments when they're trying to satisfy the constraints
Pod Topological Constraints
If you're on Kubernetes >= 1.18 you could take advantage of the beta feature PodTopologicalConstraints. I'm yet to try this primarily because we run GKE and the latest stable is 1.16. It'd be great if someone would leave some comments about their experience with this feature.
Monitoring the deployment distribution
After all this, we wanted to monitor and alert when Deployments were in an imbalanced state, so we set up a recording rule to capture the distribution per zone:
- record: "recorded:deployment_zonal_distribution"
expr: |
# Only include deployments which have a number of replicas evenly divisible by the number of availability zones
sum(count(kube_pod_info{created_by_kind="ReplicaSet", pod!~"redis-com.*|.*exporter.*"}) by (namespace)
% scalar(count(count(kube_node_labels) by (label_failure_domain_beta_kubernetes_io_zone))) == 0) by (namespace)
+ ignoring(zone) group_right
# Count all the pods and aggregate the locality info
count(
count (
kube_pod_info{created_by_kind="ReplicaSet", pod!~"redis-com.*|.*exporter.*"}
) by (namespace, pod)
*
on(pod, namespace) group_left(node, zone)
max (
kube_pod_info
* on (node) group_left(zone, region)
(
label_replace(
kube_node_labels, "zone", "$1", "label_failure_domain_beta_kubernetes_io_zone", "(.*)"
)
)
) by (pod, namespace, node, zone)
) by (namespace, zone)
# Divide it by the total number of pods for that workload
/ ignoring(zone) group_left
count(kube_pod_info{created_by_kind="ReplicaSet", pod!~"redis-com.*|.*exporter.*"}) by (namespace)We actually went as far as writing some automation which handles this alert by de-scheduling (deleting) a pod in the overloaded zone, to have Kubernetes reschedule it (hopefully) into the underloaded zone.
Uneven Zonal Distribution at Runtime
OK so let's assume you've managed to tackle all of the above, and you've landed a deployment that has replicas: 4, so 2 per zone. By default each instance of service-2 will be getting approximately 25% of the load.
What happens if one of those instances becomes unhealthy? Let's say outlierDetection kicks in (at the time of writing, outlierDetection is required for localityAwareRouting to function) and removes instance 1 of service-2 from zone-a:
With Locality Aware Routing enabled, the distribution of load to service-2 would be 50/25/25, rather than a more favourable 33/33/33 with the feature turned off. It may be fine, but it's worth being conscious of.
It is important to remember that each instance of your service in a given locality needs to be able to handle 100% of the incoming requests for that locality
Locality Aware Routing for me is an optimisation, I'd personally love to see a feature which in a failure state; it was simply disabled and reverted to global routing until all instances were healthy again.
Summary
We run circa 400 services with all sorts of different profiles. Turning on Locality Aware Routing globally for us simply isn't an option. However we were able to get a lot of benefit by enabling it for the service chain (about 10 services) which causes 90% of our cross-zone egress load.
It's an optimisation which in my opinion should be turned off by default until you identify a valuable opportunity to use it, and then use it selectively.