Alert and Incident Enrichment
Evolution of Alerting and Incident Management: Navigating Chaos in a Remote Work Era. From Desk Huddles to Digital Collaboration and how we adapted.

The last few years have been hectic. I'm sure we all agree. We've had some big changes at Auto Trader that have totally changed the way we deal with problems.
Our Alerting, and Incident Management process needed to rapidly adapt to all of this, and whilst it's been really challenging - I'm extremely proud of where we're at today. We detect and deal with problems far faster than we ever have, we can pull the right people together far quicker than we ever could in the office.
Before you delve deep into this blog, it's important you read through managing-services-metadata, as it talks about how we capture metadata about our services, their owners etc. All of that metadata feeds everything we're able to do around alerts and incidents. It also gives you the background context around our number of services, developers etc.
A little bit about our Org structure
We have a centralised Platform team, that consists of Platform Engineers who build and manage the core Platform infrastructure, and build all of the supporting tooling on top, and Operational support folks, who generally provide first line support for our users who run on top of the platform.
In terms of numbers, we have about 180 engineers who actively deploy services. The are just six of us building the platform, and about another 10 or so acting in various support capacities. So it's about a 1-10 ratio of platform to users. We have about 450 services, so that's a ratio of about 1-30 ratio of platform to services.
The engineering teams largely don't know (or care) about the fact we run on Kubernetes, use Istio, run in GCP. They treat the Auto Trader platform as a way of running their services.
What a Problem looked like 3 years ago
I think it's important to start off where we were, before we had rich service metadata, before we had Slack, and when we worked primarily in an office. It looked something like this:
- We detected, or we were told about a problem. Teams had dashboards up on their monitors at the end of the banks of their desks so they could quickly eyeball graphs going in the wrong direction. The Operations Engineers has some synthetic monitoring for key parts of our estate.
- The Operations Engineers typically knew which Squad a service belonged too, from memory and past experience (or naming convention). They typically knew where that team sat, so they could walk over to their desk.
- We'd grab any additional folks we think may help us resolve it, and we'd huddle around a bank of desks until it was resolved.
- The Operations Engineers would drop an email to relevant parties if further communication was required.
Things were relatively rosey actually - sure they could be improved a bit, but it worked for us. But then things got a little more chaotic.
The Global Pandemic
We were office based, and then suddenly, we weren't. No longer could we grab someone from their desk, huddle around. We had to adapt rapidly to communicating effectively, digitally.
We had started to use Slack just before the pandemic struck, but its use has exploded since then. We quickly switched to white boarding tools such as Miro to visually collaborate.
Internal Org Changes
Ownership of services changed, previously every service was owned by a squad, and the relationship of squads to the Operations teams was done quite personally by an Operations Engineer (a Squad Buddy). Now service ownership was much more distributed, depending on the streams of work the broader organisation had committed to working on. Those streams change frequently and therefore so can the maintainers of the service. No longer was it possible to simply remember who the key point of contact was for a service. We needed metadata to track it as it changed.
Rapid Growth of Services
The new Platform enabled complete end to end, self service. Teams could create and destroy services as they see fit. It also opened the door to new types of services, previously we only supported Java, suddenly the deployable artefact was Docker and teams could run (within reason) whatever they want, More and more services were being deployed every day. Teams were breaking up monoliths into smaller services. Again, we needed metadata to help us keep on top of this.
What things look like now: Alerts
Let's start with alerts. As I mentioned above teams were used to eyeball graphs that were in front of them at their desks, or being told by someone nearby them that theirs a problem with their service. Now we wanted to get the alerts in front of the right people, as quickly as possible.
There are several sources for alert data, I've shown a few of them here. They all send their alerts to Skippr. Skippr in turn queries the Metadata (remember - read the metadata blog) and enriches the incoming alert with information about the services, such as its maintainers. It also queries other sources of enrichment such as Jaeger (traces), ElasticSearch (App logs) to find useful information to help make the alert as actionable as possible.
It then forwards that enriched consistent alert on to Slack and/or Pager Duty.
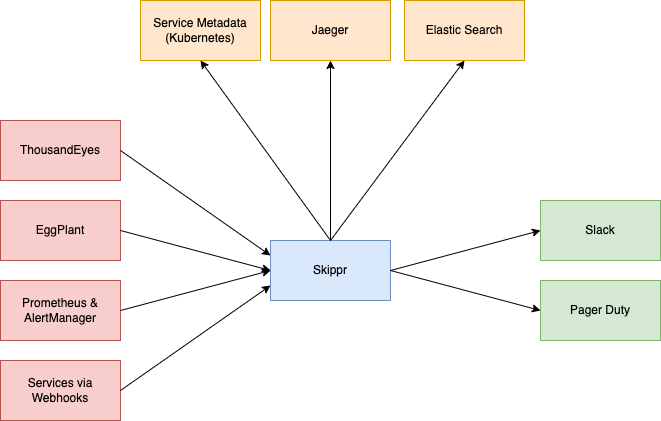
The correlating point across all of these incoming alerts is the application name. Consistently stored data is absolutely key, we don't give people the ability to control their application name in logs, metrics, or service data, it's enforced at the platform level to always be the same.
Here's an example of some enriched alerts. You can see the alert came in (originally from Prometheus) for an application - kubitzer, at this point Skippr queries the Slack API to see if there is a UserGroup named kubitzer-maintainers. Remember, those user groups are created automatically by our metadata management. If there is, it's added to the alert templating.
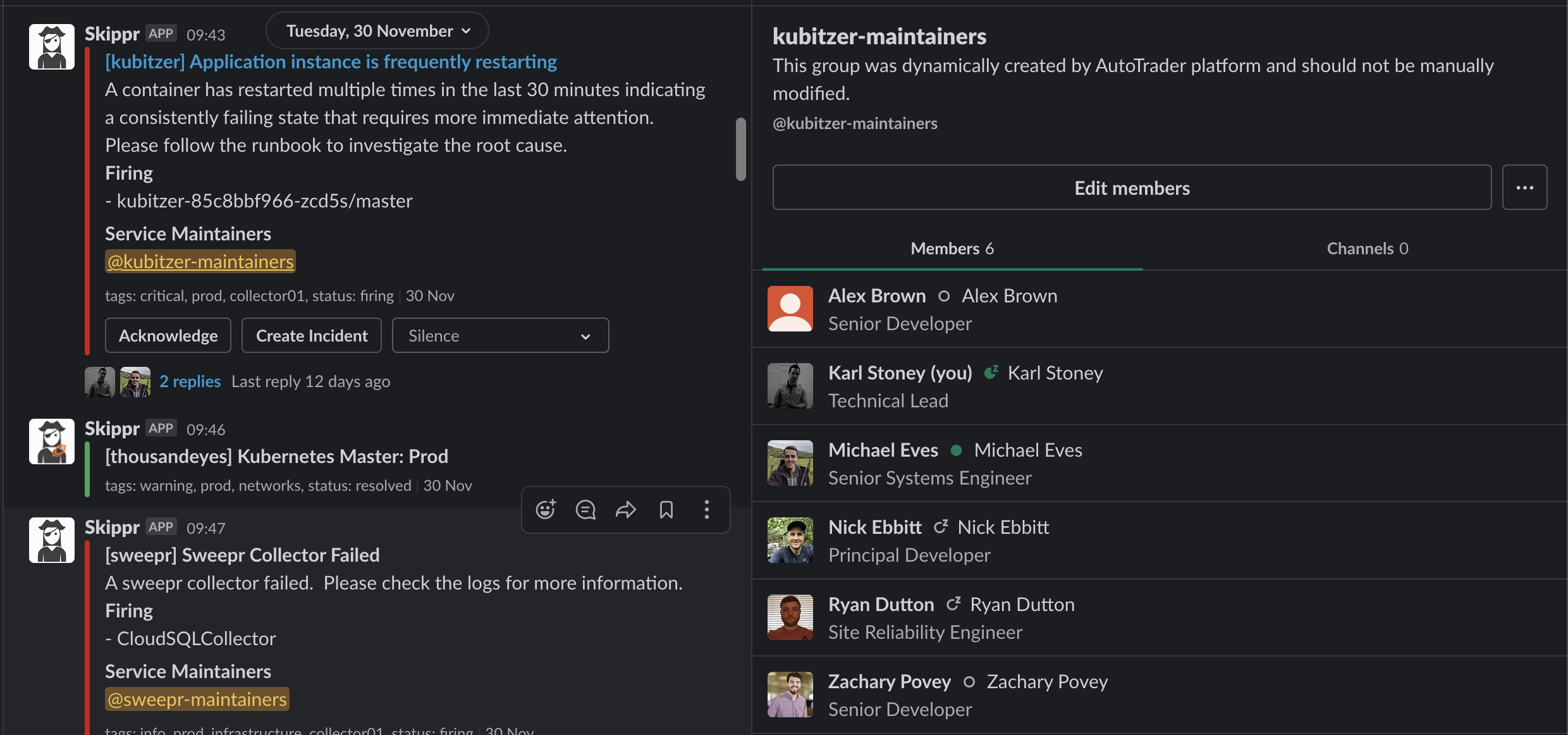
Great! At this point we have an alert that's immediately tagging the known maintainers of that service. Those maintainers change (updated in the yaml) the rest of the alerting and notification system just works.
However, we want to ensure those people who get pinged immediately have as much information as possible. That's why Skippr will also query supporting tools like Jaeger, and provide context on the alert which may help. In this example the alert was about high error rates, you can see Skippr has queried Jaeger, and found some errors, it provides a quick link to those traces.
What things look like now: Incidents
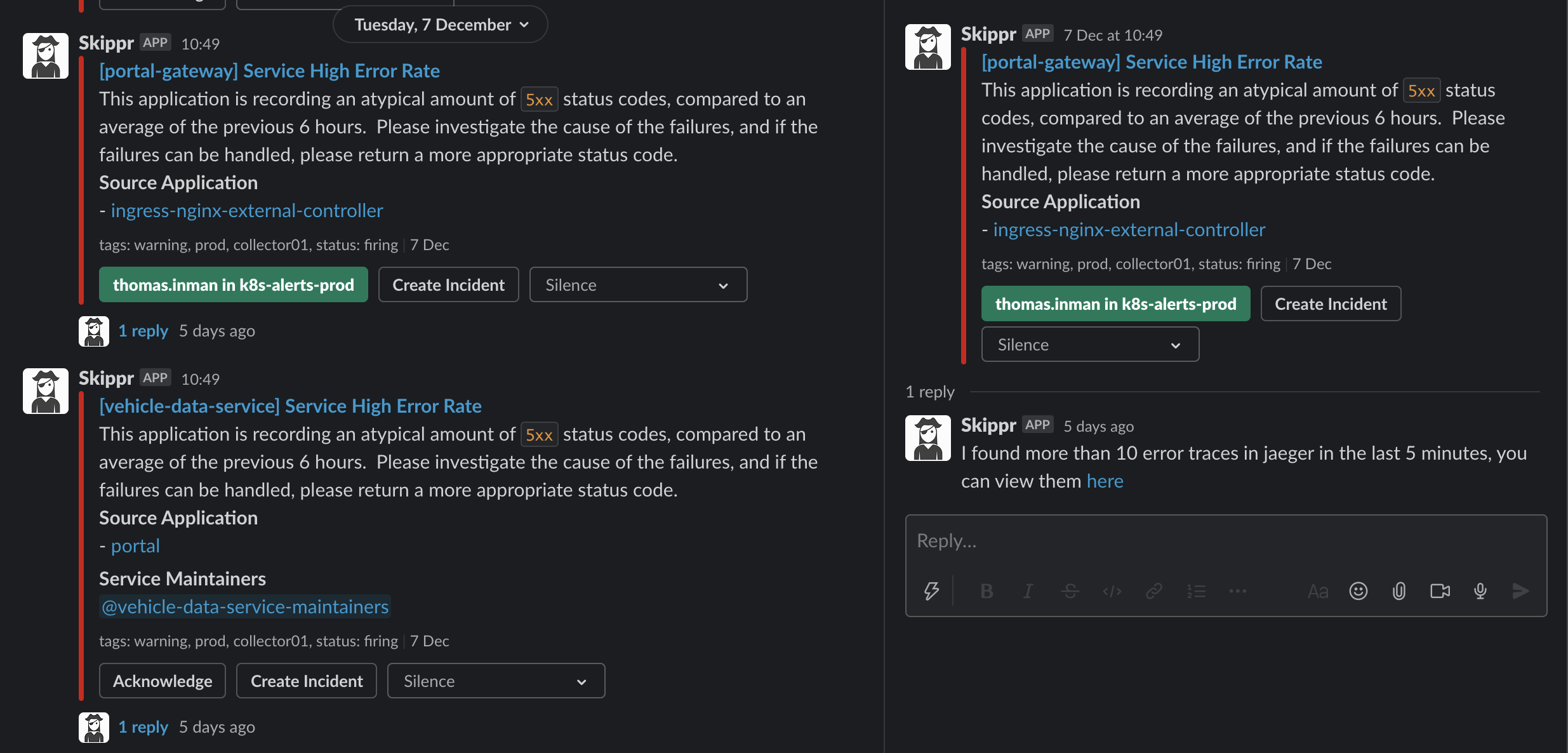
Next we wanted to tackle that "quickly grab the right people and huddle around a desk" mentality, but remotely. You may have noticed the "Create Incident" button on the above alerts. Clicking that button pops up a quick form with some defaulted values:
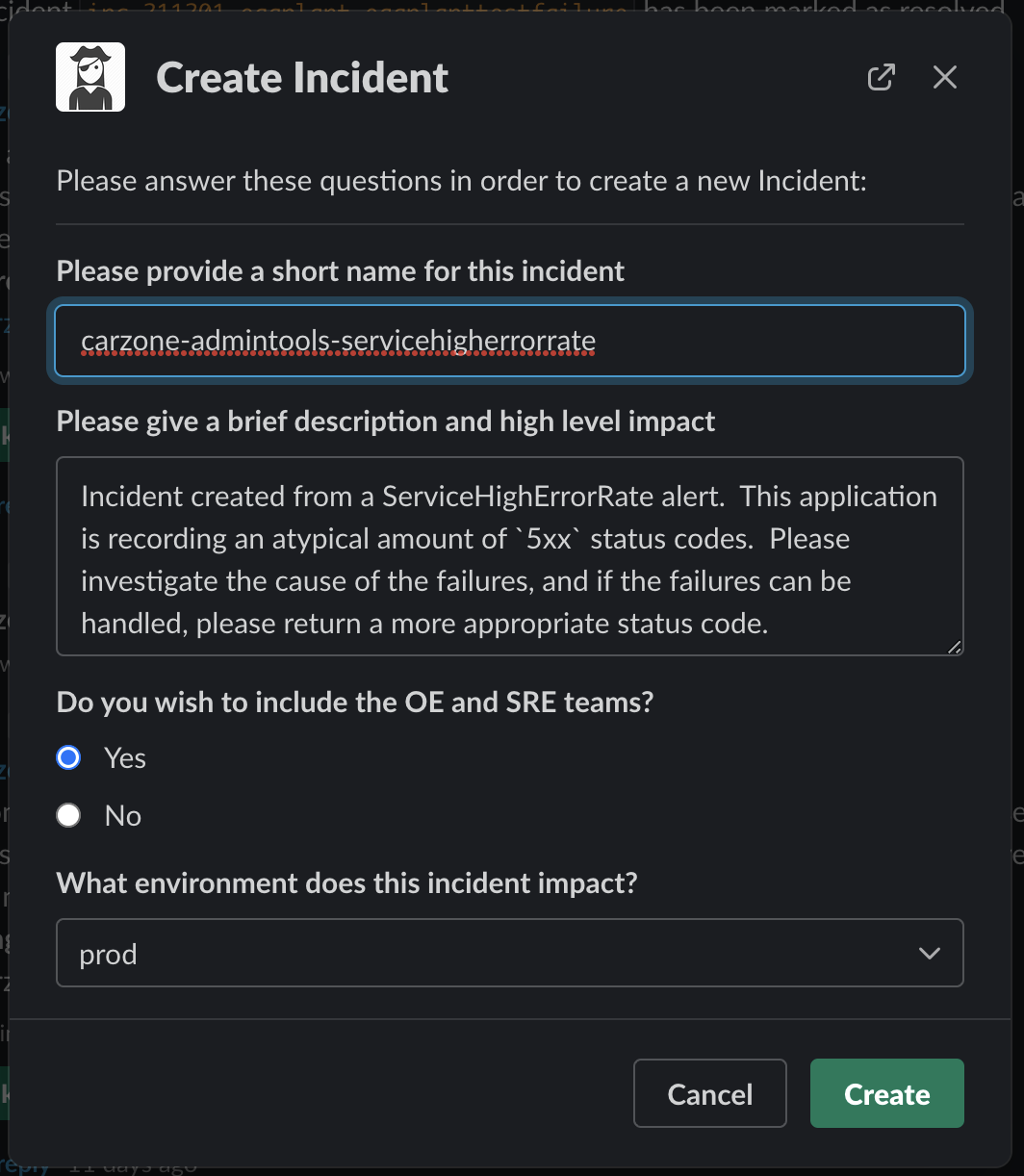
Clicking create will create an inc- slack channel, and automatically invite the owner and maintainers of the service. During that incident, if we believe other services are part of it - we can type @Skippr include app <application name>. This in turn again looks up the owners and maintainers of that service, and invites them in too. You can see me doing that here with kubitzer:
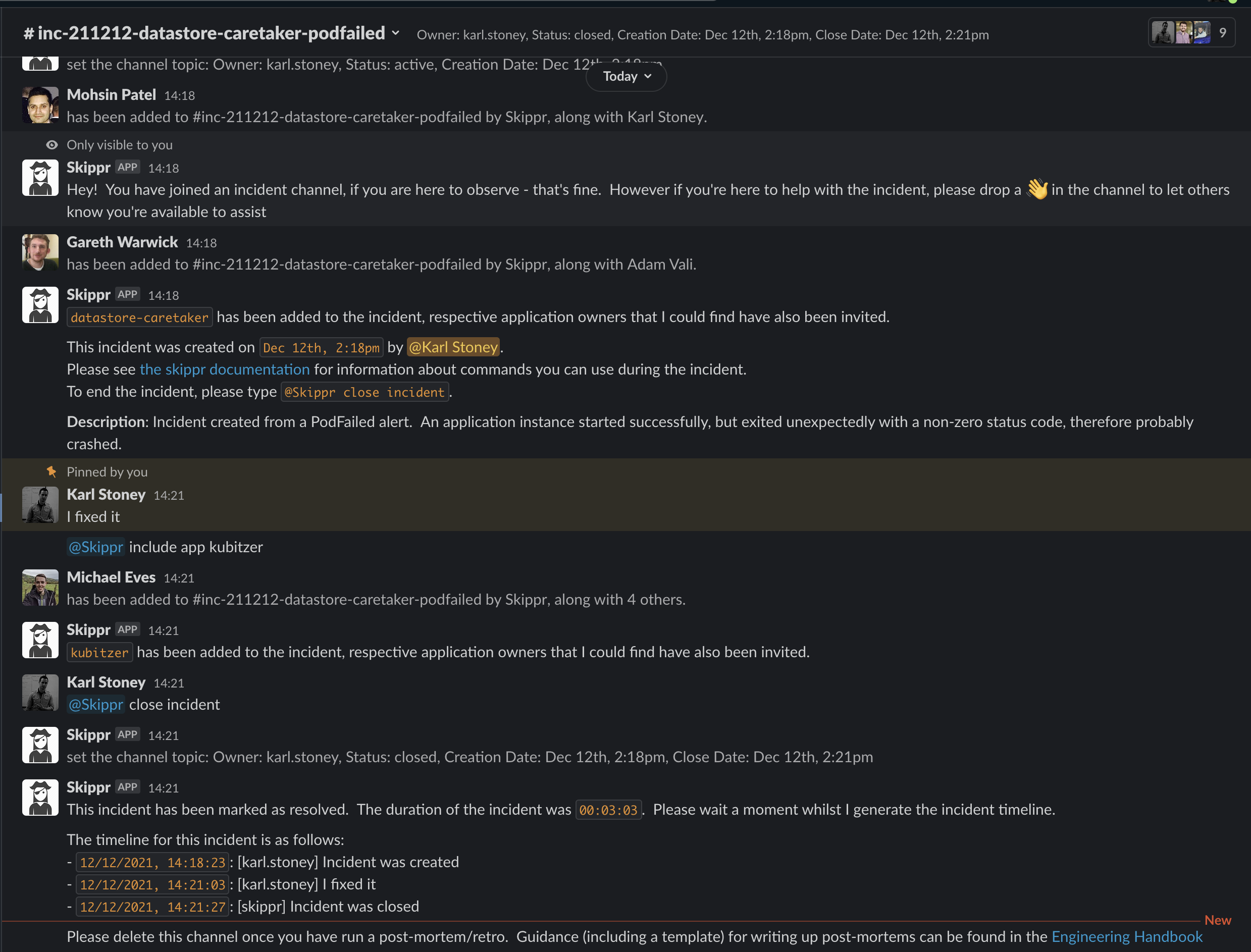
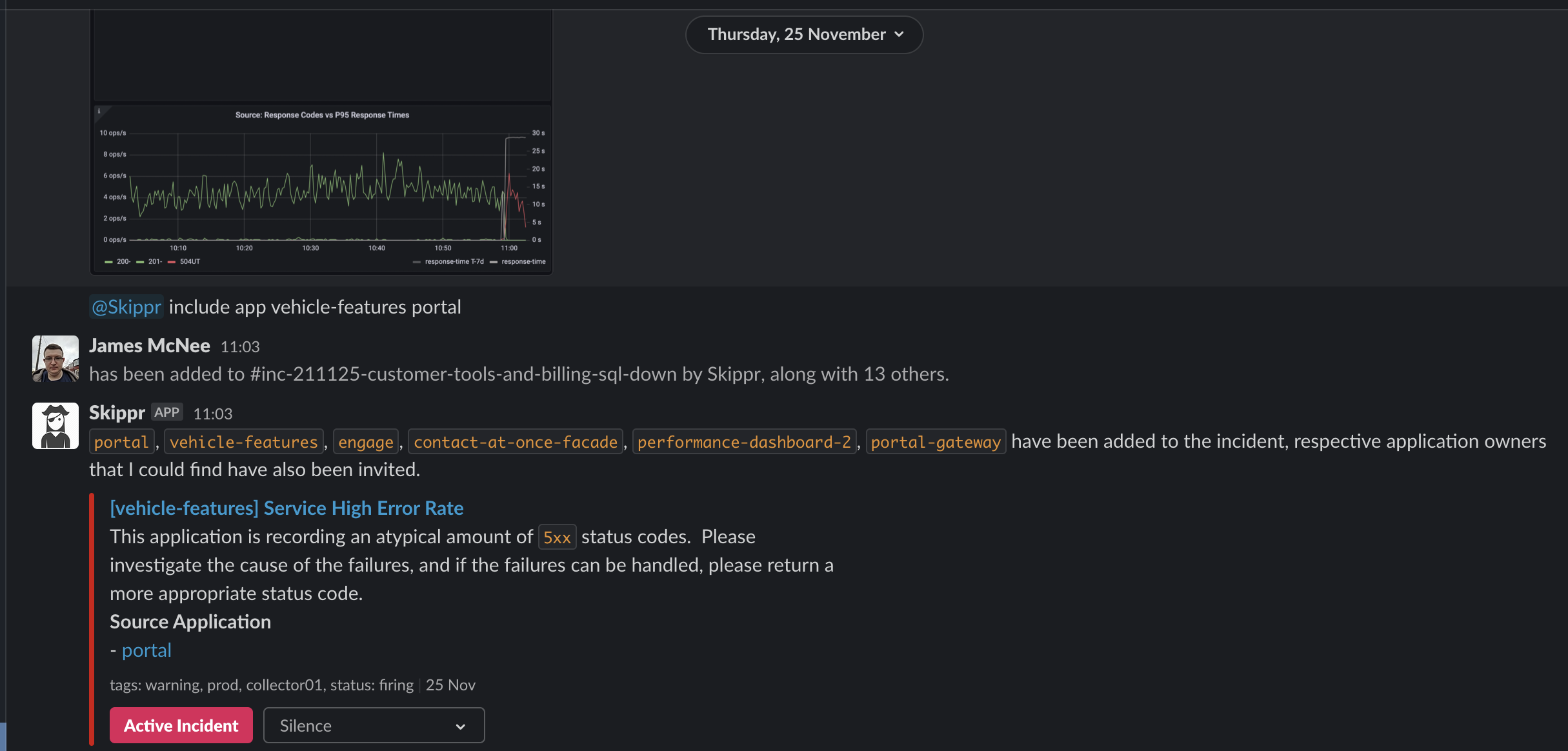
Another advantage to "Including" an application in an incident is that we automatically tag all alerts from that point forward as being part of an active incident, those alerts also get forwarded to the incident channel whilst the incident is open. As we have a broad microservice architecture, Skippr will also look at the NetworkPolicy for the service, and include any application that immediately depends on it. Here you can see my including vehicle-features and portal, but Skippr pulling in things that depend on those applications too:
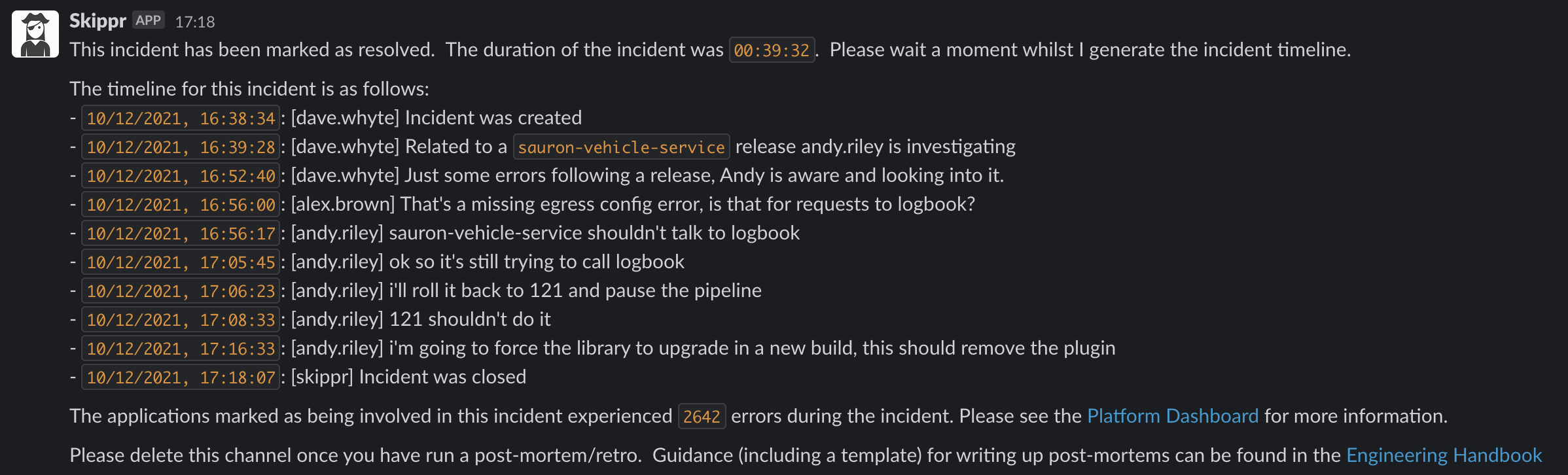
Slack channels can sometimes get quite noisy, so we pin key items as we go. When the incident is closed, Skippr will look up all the pinned items in that channel and use them to generate a high level timeline that can be referenced in the retrospective.
The whole process is designed to be really quick, really light weight. People don't need to guess who they need to invite, Skippr handles it for them providing they give the name of the applications. As a result we actually have far more "Incidents" these days, not because we're creating more problems, but because the process is so simple and quick its by far the easiest way for us to collaborate remotely as a group.