Cold Start Applications
Using Istio, Kubernetes and Prometheus to build dynamically scaling infrastructure that can scale unused workloads to zero.

I'm continually looking for ways to optimise our compute usage in cloud. We have about 450 services in total, and quite a few of these are admin apps that are accessed somewhat infrequently. It makes little sense to keep them running 24/7, so taking inspiration from serverless capabilities like CloudRun, I wanted to see if I could implement a simple cold start capability on our platform.
I didn't want to make any significant architectural changes, or bring in dependencies on additional tooling if I could avoid it, so I decided to try and implement something using our existing tech stack:
It only took a couple of hours to get something pretty functional working, so I thought it'd be an interesting blog! I can't open source the code because it uses a bunch of internally built libraries nuanced to Auto Trader, but hopefully you can see it's relatively trivial for you to implement it yourself.
In this blog I'll show how I write a small service that sits along side our workloads. It'll query request data from Prometheus to make scaling decisions, and adjust the workloads VirtualService to handle requests itself when it is scaled down.
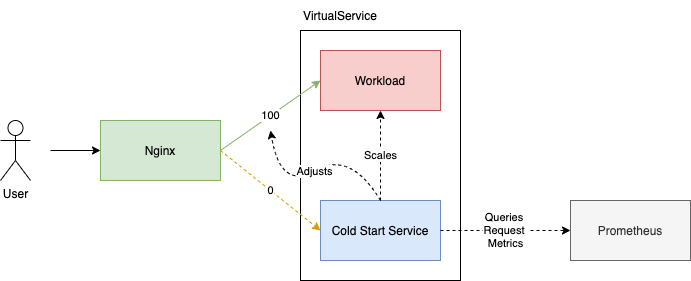
Auto Scaling Down
So the first thing we need to do is decide which services we want to enable this capability for. I decided to use a CustomResourceDefinition in the namespace of an application to turn on the feature, but you could equally use an annotation on the Deployment or VirtualService. Here's an example of me describing this feature for our test service, monkeynetes.
apiVersion: platform-cold-start.io/v1
kind: Target
metadata:
name: monkeynetes
namespace: monkeynetes
spec:
deployment: monkeynetes
virtualService: monkeynetes-appThe next thing I did was write a simple application (Cold Start Service in the diagram above) that periodically (every hour) queries the Istio Observability metrics in prometheus to get a list of all services that have no requests to them in the last hour:
sum(
increase(
istio_requests_total[1h]
)
) by (destination_service) == 0Which gives us a nice list like so:
{destination_service="app.monkeynetes.svc.cluster.local"} 0
... etcNow we take all of the target.platform-cold-start.io/v1 resources and filter them against the list we got back from Prometheus, to identify Targets that have had no requests in the last hour. You can do that by matching the .spec.hosts to the destination_service label above.
At this point we know which services are candidates for scaling, we go ahead and do that by patching the Deployment.spec.replicas to 0.
Automatically Scaling Up
Scaling down is the easy part, the slightly more difficult part is scaling back up in response to a client request. This is where we use the VirtualService of the destination workload to temporarily route traffic to the service responsible for scaling back up. In the above bit of code, when the service is scaled to 0 we also append a new destination on the default route which temporarily routes all traffic to the holding service:
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: monkeynetes-app
namespace: monkeynetes
spec:
hosts:
- app
- app.monkeynetes.testing.k8.atcloud.io
http:
- match:
- port: 80
name: default
route:
- destination:
host: app
port:
number: 80
weight: 0
- destination:
host: app.platform-cold-start.svc.cluster.local
port:
number: 80
headers:
request:
set:
x-platform-cold-start: monkeynetes
x-platform-cold-start-namespace: monkeynetes
weight: 100
timeout: 10sNote what's going on here, we've added a destination for the default route which has a weight of 100 (all traffic) to route to our Cold Start Service, app.platform-cold-start.svc.cluster.local. We also append a couple of request headers to help the cold start service identify the incoming request. We could also use request.host, but I opt'd for a header.
That service does a couple of simple things:
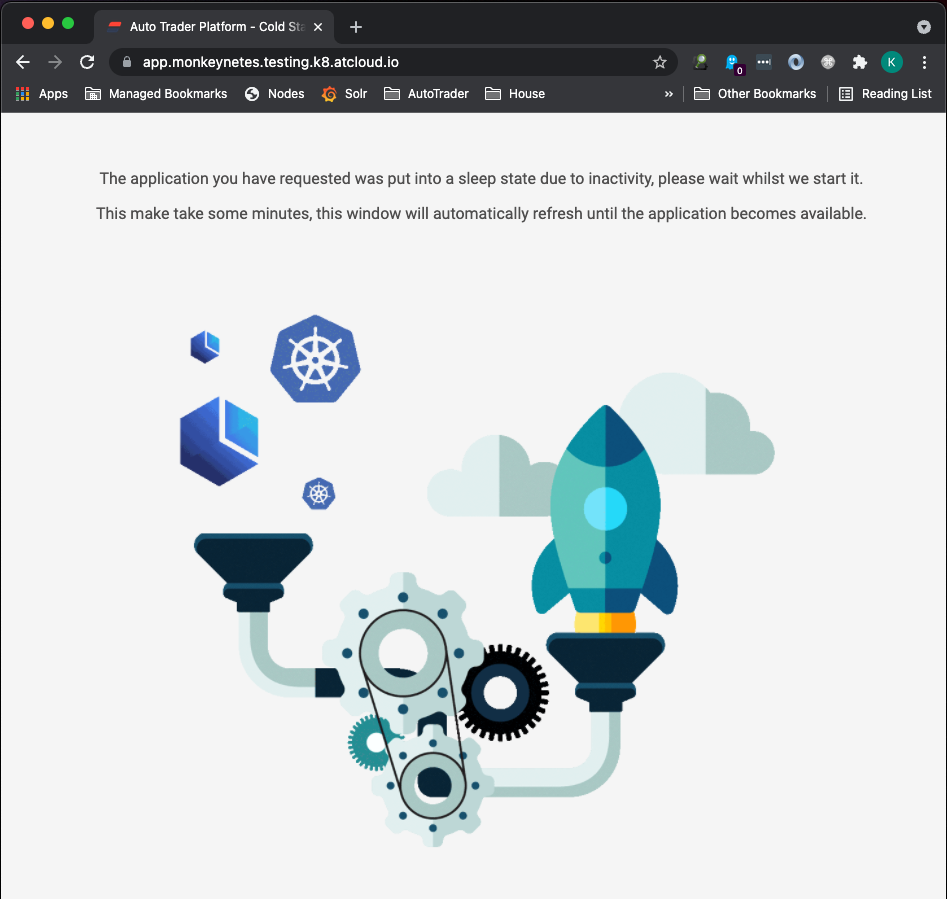
- Accepts the incoming request, and shows a holding page to the user:
- Uses the
x-platform-cold-startheaders to identify thetarget.platform-cold-start.io/v1resource. - Scales the referenced
Deploymentup. - Waits for the
Deploymentand associated pods to be in a fully ready state, and then switches the route weighting back to the application.
{"timestamp":"2021-11-10T09:43:05.757Z","level":"info","module":"ColdStartController","message":"handling cold start request..."}
{"timestamp":"2021-11-10T09:42:54.449Z","level":"info","module":"ColdStart","message":"waiting for deployment to fully roll out","namespace":"monkeynetes","name":"monkeynetes"}
{"timestamp":"2021-11-10T09:43:48.700Z","level":"info","module":"client","message":"rollout complete","namespace":"monkeynetes","name":"monkeynetes","kind":"Deployment"}
{"timestamp":"2021-11-10T09:43:48.721Z","level":"info","module":"ColdStart","message":"setting cold start route weight to 0","namespace":"monkeynetes","name":"monkeynetes"}
The holding page that is returned to the user has a meta refresh of 10 seconds:
<meta http-equiv="refresh" content="10">Which means as soon as the VirtualService route has been updated (because the deployment is back up), the user will see the application:

And that's it!
Conclusion
This was a cool little experiment that shows how powerful the Kubernetes, Istio and Prometheus stack is, and how you can implement some really powerful capabilities with relatively little effort.
It is also extremely extensible, and can be enabled on any service by simply adding the CustomResourceDefinition to the namespace of the application we want to scale.