Building a PR Review Agent
Building a PR review agent using Gemini CLI on Kubernetes

I've been working a lot with AI recently, both from a product perspective working on Autotrader's Co Driver offering, but also as a Developer, using the myriad of code-assist style tools and agents out there.
It's been a love-hate relationship, one minute I see the future, the next minute I git revert everything it's done and just write it myself. My experience so far tells me if you're working on some code, and have a good set of tests, and write some new tests to describe new functionality - it'll be pretty great. If you give it a blank slate, it'll be hit and miss (more miss).
Given that, where I find AI to shine - particularly with the latest models (gemini-2.5-pro and gpt-5-codex) is reviewing or tweaking existing implementations, because it is reviewing existing code it is already constrained. I have found myself absolutely loving the cycle of me writing the code, but the AI reviewing it - that might be looking for bugs, highlighting tests you may have missed, optimisations or readability improvements etc. It feels like the best of both worlds, I truly own the code I put into production, but I have an assistant looking for my inevitable mistakes.
I already use gpt-5-codex in my IDE - so I began to use gemini-cli to perform final reviews. There's absolutely no science behind this, but I quite liked the idea of using a different model to perform code reviews than the one I used whilst writing the code 🤷.
In this blob I'm going to explore how I implemented a custom PR review process on GitHub enterprise, and extended into a platform feature any of our teams can consume with a few lines of config in their repository.
Async Github PR review process
As the review process can be a little slow I tend to treat it as asynchronous. Eg I kick off Gemini or GPT-5-Codex reviewing my recent N commits and work on something else whilst it is churning away, going back to its review later. So I thought - why not do this on a PR review in GitHub? Turns out that is a solved problem with gemini-cli, you can easily integrate it into github with /setup-github, see more info here https://github.com/google-github-actions/run-gemini-cli.
However, that doesn't fit our environment for a few reasons:
- We have a rich PaaS "Delivery Platform" that sits on top of GHE that handles built/test/deploy of our services with minimal configuration required for our engineers - think of it as our own internal Vercel/Heroku etc. The last thing I want is loads of
.githubconfiguration in every repo if I was to make this available for everyone as Platform feature. - We use Github Enterprise, and don't have actions enabled. Our custom tooling takes care of all aspects of the build, test deploy pipeline.
- I regularly find being constrained by the off-the-shelf offerings to be limiting when I want to customise specifically for our use case. Our platform is hyper optimised for Developer Experience so any surface area the users interact with is typically bespoke so we can ensure it's perfect and as low-configuration as possible for our use case.
- I like to build some things myself to learn how it all pieces together, especially in such a fast moving space.
So I set about building my own simplified version bespoke to our use case, and this is how it came out:
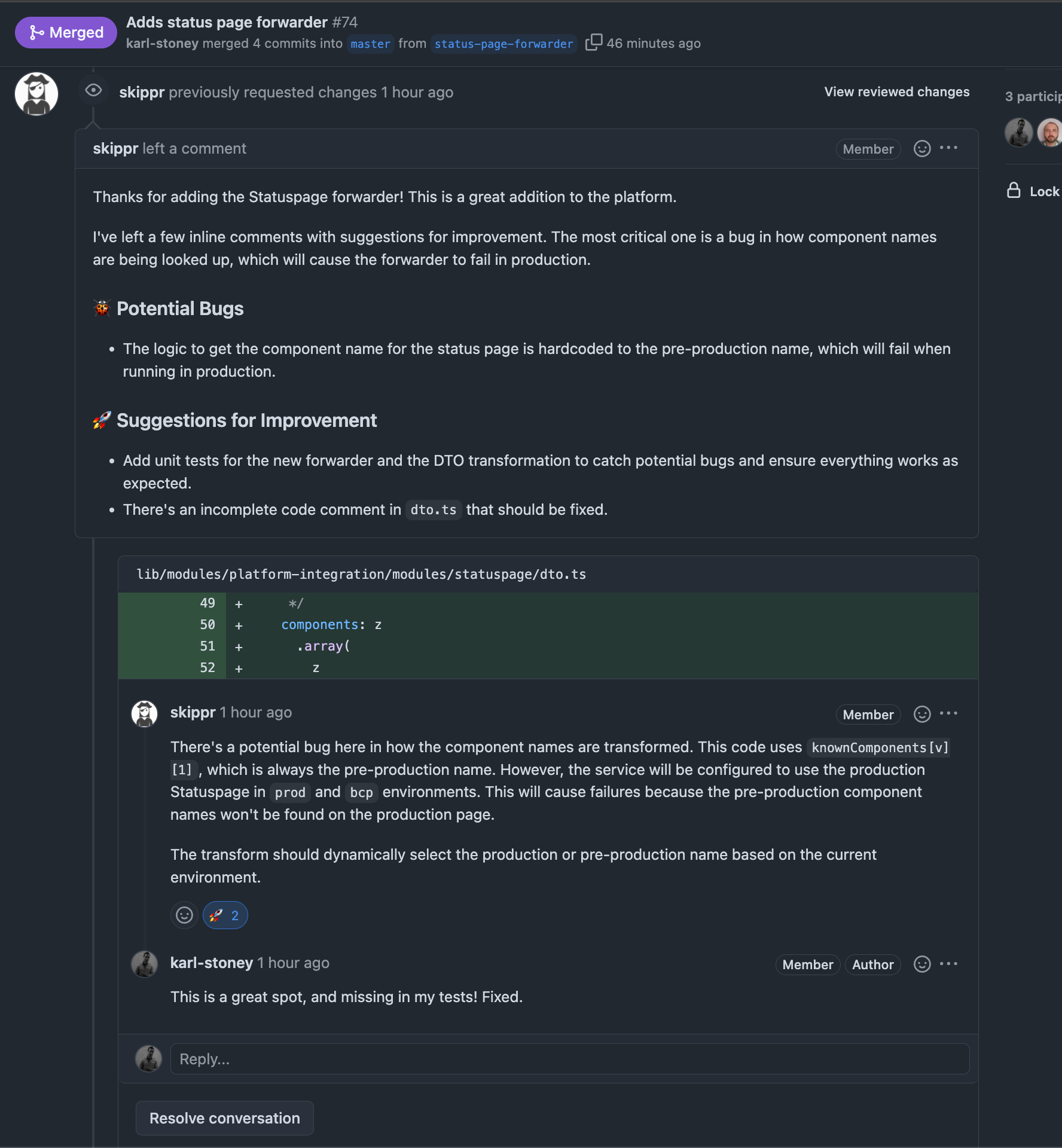
Pretty dam neat!
High Level Architecture
So diving right into it, this is what happens:
- A webhook from GHE to our API on PR event.
- Our API fetches their platform configuration file (
shippr.yaml) from the repo, and checks if they have code assist enabled. - If it does, it schedules a Job on Kubernetes to perform the code review.
- The job:
- Clones the repository at the PR source & destination SHA's.
- Sets up a gemini instruction file, templated from the configuration in their
shippr.yaml. - Invokes
gemini-cliinstructing it to perform the review.
Shippr.yaml
Any repo deployed on our platform has a shippr.yaml, this is where they configure any of our platform capabilities, like dependency checking, etc. I extended this to support codeAssist:
codeAssist:
pullRequests:
enabled: true
canApprove: true
canMerge: true
canRequestChanges: true
on:
- openedThe code-review api is responsible for receiving the incoming webhook from Github and then fetching the shippr.yaml from the repo to check if it should schedule a pull request. If all is well, we create a Kubernetes Job for that specific PR.
Kubernetes Job
The docker container for the job has a few things in it:
- gemini-cli obviously, as that is doing the bulk of the work.
- github-mcp-server to enable gemini to update the PR, fetch the diff, etc.
git-core, so we can clone the repo.- A few scripts to pull everything together.
Gemini CLI installation
Installation of gemini-cli is really simple. I use node so npm i -g @google/[email protected]. You'll also need to configure the ~/.gemini/settings.json too, this is how I have it set up to ensure headless reviews (eg no confirmation etc):
{
"tools": {
"autoAccept": true,
"useRipgrep": true
},
"general": {
"disableAutoUpdate": true
},
"security": {
"folderTrust": {
"featureEnabled": false,
"enabled": true
},
"auth": {
"selectedType": "vertex-ai"
}
},
"ui": {
"hideTips": true,
"hideBanner": true,
"hideFooter": true
},
"model": {
"maxSessionTurns": 100
}
}gemini settings for headless environment
Github MCP
The MCP server for Github really is excellent, and gemini-cli works beautifully with it. We restrict the tools that gemini-cli has access to, primarily to reduce the amount of tokens consumed by defining tools but also limit the scope of what the cli can do. Again this goes in your ~/.gemini/settings.json:
{
...,
"mcpServers": {
"github_can_merge": {
"command": "/usr/local/bin/github-mcp-server",
"args": ["stdio"],
"trust": true,
"includeTools": [
"get_issue",
"get_issue_comments",
"get_pull_request_review_comments",
"get_pull_request_reviews",
"get_pull_request_status",
"get_pull_request",
"list_issues",
"list_pull_requests",
"search_issues",
"search_pull_requests",
"add_comment_to_pending_review",
"add_issue_comment",
"create_and_submit_pull_request_review",
"create_pending_pull_request_review",
"submit_pending_pull_request_review",
"update_issue",
"update_pull_request",
"merge_pull_request"
],
"env": {
"GITHUB_PERSONAL_ACCESS_TOKEN": "$GITHUB_TOKEN",
"GITHUB_HOST": "$GITHUB_HOST"
}
}
}
}
gemini settings for github mcp server configuration
Obviously the permissions on your Personal Access Token need to match the tools here.
Running the job
When the job runs, a high level script orchestrates the whole process, it's responsible for:
- Templates an instruction file that Gemini is expected to follow.
- Clones the repo at the right point and generates the diff.
- Executing
gemini-cliand collecting the results.
I'm not going to share the script because it's actually a small nodejs app, and will be bespoke to your implementation. Instead i'll talk through the key components you can probably use.
The Instruction File
We generate an instruction file for Gemini to follow, rather than passing it all via stdin - because it's reasonably verbose. We template this using handlebars based on your shippr configuration (eg canApprove, canMerge, etc). The instruction is pretty length, so I've put it in a gist here:

Gemini PR Review Prompt
The meat of the complexity is in the prompt. It is broken down into sections which are loosely:
- Core Task. Explaining the persona of the bot, and what is expected of them
- Review Principles. The things that we are wanting the bot to spot, and importantly things we do not care about (false positives we have noticed from previous reviews).
- Context. A structured process for gathering context. We instruct the bot to use the GitHub MCP server to read the PR, the diff, the comments, previous reviews. We instruct it to consider the local
copilot-instructions.mdandGEMINI.mdfiles, read theREADME.mdof the app, fetch any Architectural Decision Records, etc. - Execution Plan. A structured process with thinking to do the actual review process.
- Output. How to respond in different scenarios, for example - an initial review vs a re-review. We also tell the bot if it should approve or just comment, or can it merge. We instruct the bot to prefer inline comments over massive review documents, etc.
These instructions are shared for all reviews, however we facilitate per-repo nuances by instruction the bot to read any local gemini or copilot instruction files:
- [ ] Look for existing `GEMINI.md` or `.github/copilot-instruction.md` files in `{{codeDir}}`. These may contain important information to help you understand the repo. However they may also include instructions about building or running the application, as that is outside of your remit, you should ignore Fetching the Repo & Diff
We want to be able to provide the LLM a concise diff. I started by simply downloading the .diff file from the GitHub API, but we ran into some issues with this approach:
- GitHub's API fails when the diff was huge (
406). - The
diffis very verbose, which equals more tokens. For example, moving a file results in many lines for both the delete and the add, causing Gemini to have issues processing it.
As a result we moved to just using git ourselves to calculate the diff exactly how we want it. We calculate the merge-base to be able to produce a Github like diff file.
# Set up the working directory
echo "Cloning from ${GITHUB_ORG}/${GITHUB_REPO} into ${CODE_DIR}"
rm -rf "${CODE_DIR}"
mkdir -p "${CODE_DIR}"
cd "${CODE_DIR}" || exit 1
git config --global init.defaultBranch master
git init
git remote add origin "${GITHUB_HOST}/${GITHUB_ORG}/${GITHUB_REPO}.git"
INITIAL_FETCH_DEPTH=${INITIAL_FETCH_DEPTH:-10}
echo "Fetching destination commit ${DESTINATION_SHA} (depth=${INITIAL_FETCH_DEPTH})"
git fetch -q origin "${DESTINATION_SHA}" --depth="${INITIAL_FETCH_DEPTH}"
git checkout -b destination FETCH_HEAD
echo "Fetching source commit ${SOURCE_SHA} (depth=${INITIAL_FETCH_DEPTH})"
git fetch -q origin "${SOURCE_SHA}" --depth="${INITIAL_FETCH_DEPTH}"
git checkout -b source FETCH_HEAD
# Compute merge-base for a GitHub-like diff (merge-base..source) so we don't
# incorrectly show unrelated deletions from the up-to-date destination branch.
MERGE_BASE=""
echo "Attempting to compute merge-base between 'source' and 'destination'..."
DEPTH=${INITIAL_FETCH_DEPTH}
ATTEMPT=1
# We'll try a few deepen cycles then unshallow as a last resort.
while [ $ATTEMPT -le 5 ]; do
set +e
MERGE_BASE=$(git merge-base source destination 2>/dev/null || true)
set -e
if [ -n "${MERGE_BASE}" ]; then
echo "Found merge-base: ${MERGE_BASE} (after depth ${DEPTH})"
break
fi
if [ $ATTEMPT -lt 5 ]; then
if [ $ATTEMPT -lt 4 ]; then
# Deepen history
NEW_DEPTH=$(( DEPTH * 2 ))
echo "Deepening history to ${NEW_DEPTH} to locate merge-base (attempt ${ATTEMPT})"
git fetch -q origin "${DESTINATION_SHA}" --deepen=$(( NEW_DEPTH - DEPTH )) || true
git fetch -q origin "${SOURCE_SHA}" --deepen=$(( NEW_DEPTH - DEPTH )) || true
DEPTH=${NEW_DEPTH}
else
echo "Unable to find merge-base with shallow history; unshallowing..."
git fetch -q origin "${DESTINATION_SHA}" --unshallow || true
git fetch -q origin "${SOURCE_SHA}" --unshallow || true
fi
fi
ATTEMPT=$(( ATTEMPT + 1 ))
done
if [ -z "${MERGE_BASE}" ]; then
echo "WARNING: Could not determine merge-base; falling back to destination head for diff base" >&2
fiCode to find the merge-base
Once we've got the repo setup, we can generate the diff. You can see here how being in full control of the diff we can reduce the token count significantly:
git diff \
-D \
-B \
-M \
--ignore-all-space \
--ignore-blank-lines \
--unified=2 \
--diff-algorithm=histogram \
"${DIFF_BASE_REF}" source -- \
. \
':(exclude,glob)**/*-lock.json' \
':(exclude,glob)**/*-lock.yaml' \
...etc
> "${DIFF_LOCATION}"Code to generate a concise git diff
Execution Time!
Then finally, we let Gemini go with:
${GEMINI_BIN} \
--approval-mode=auto_edit \
--telemetry=false \
--model=gemini-2.5-pro \
--include-directories="${CODE_DIR}" \
--include-directories="${CONTEXT_DIR}" \
--include-directories=. \
--allowed-mcp-server-names="${GITHUB_MCP_SERVER_NAME}" \
-p "Read ${PR_INSTRUCTIONS_LOCATION}. Follow it exactly. When ALL required outputs are complete you MUST print ONLY the line: \"REVIEW_COMPLETE_SENTINEL\" then exit 0 immediately. If you cannot, exit non-zero. Do not wait for any further input." \
> "${GEMINI_SUMMARY_LOCATION}"And that's it, a few minutes later the review appears in Github!
Context is King
At this point we had a pretty reasonable PR review process, however it was reliant on inferring context from the PR & Diff alone, which sometimes led to it making incorrect assumptions. We decided there were two more sources of information that we needed to:
- Any associated github issues linked in the PR.
- Comments from previous reviews.
- Any associated jira tickets linked in the PR.
- Any relevant Architectural Decision Records.
Github Context
The excellent github-mcp-server made the first two super easy to tackle, we simply added the following to our instructions file:
- [ ] You must fetch all PR review comments using `get_issue_comments`.
- [ ] You must fetch any existing reviews that have been done with `get_pull_request_reviews`
- [ ] You must then fetch any comments from these reviews with `get_pull_request_review_comments`.
- [ ] If the PR, or comments reference other GitHub issues, you should read those issues using your `get_issue` GitHub tool understand the problem the PR was trying to address.This set of instructions ensured that gemini fetched all relevant context before starting its review.
Jira Context
Another solid source of context was Jira issues. I wasn't happy with any of the MCP servers I found for this, so decided to write our own - which is incredibly easy to do:
import { McpServer } from '@modelcontextprotocol/sdk/server/mcp.js'
import { StdioServerTransport } from '@modelcontextprotocol/sdk/server/stdio.js'
import sanitizeHtml from 'sanitize-html'
import { z } from 'zod-v3'
import { Atlassian } from 'lib/clients/atlassian'
const atlassian = new Atlassian()
const server = new McpServer({
name: 'autotrader',
version: '1.0.0',
description: 'Autotrader MCP Tools to support Code Review'
})
server.registerTool(
'jira_get_issue',
{
title: 'Jira: Get Issue',
description: 'Get a Jira issue by ID',
inputSchema: { issueId: z.string() }
},
async ({ issueId }) => {
const issue = await atlassian.getIssue(issueId, ['description'])
const sanitizedDescription = sanitizeHtml(
issue.renderedFields.description,
{
allowedTags: [],
allowedAttributes: {}
}
)
return {
content: [
{
type: 'text',
text: sanitizedDescription
}
]
}
}
)
const transport = new StdioServerTransport()
await server.connect(transport)Simple Atlassian Jira Ticket MCP Server
Really simple but does the job, it:
- Exposes a function to get a Jira ticket by ID
- Uses
santize-htmlto clean junk tokens out of the response
You then add that to gemini-cli's configuration:
{
...
"mcpServers": {
"autotrader": {
"command": "/usr/bin/node",
"args": ["/usr/local/autotrader/app/lib/mcp.js"],
"trust": true,
"env": {
"ATLASSIAN_USERNAME": "$ATLASSIAN_USERNAME",
"ATLASSIAN_API_TOKEN": "$ATLASSIAN_API_TOKEN"
}
}
}And then instruct the cli to use it in our instructions file:
- [ ] If the PR, or comments reference a Jira issue in the description (it will start with `https://autotrader.atlassian.net`), you must then fetch the issue with your `jira_get_issue` tool to read the associated issue.The result:
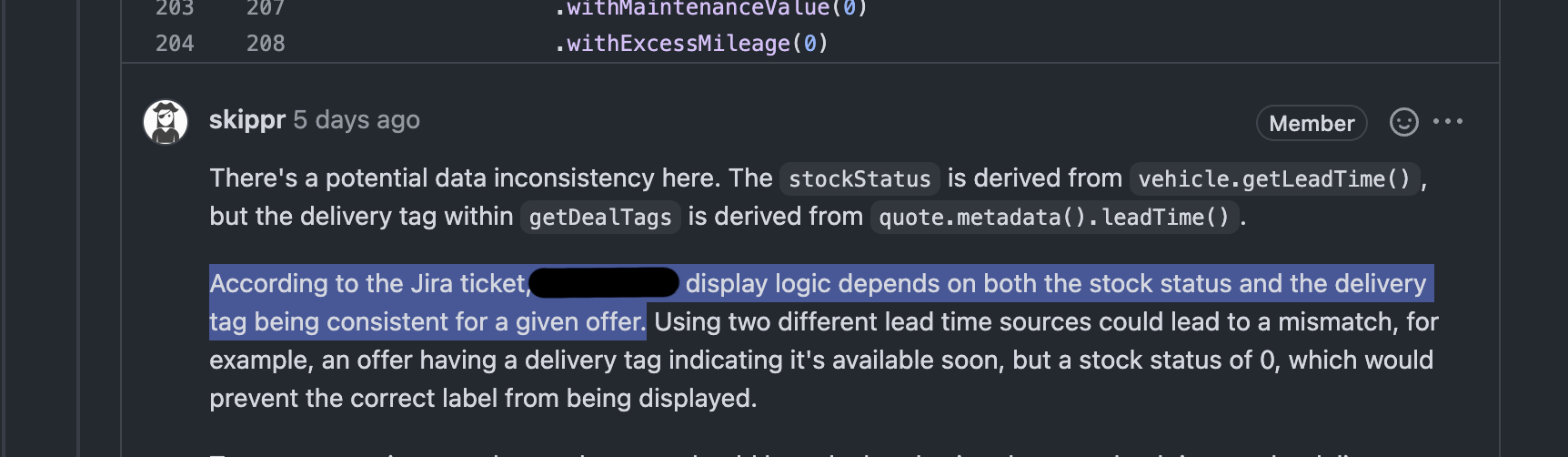
A bot that also considers the Jira ticket context! Wonderful!
Architectural Decision Records
We try to use ADRs, and we store them in two places - either local to the repository or as issues in a separate Github project. We instruct gemini to consider them as part of their review:
Some repositories will store ADRs locally to the repository; look for ADRs (perhaps in `{{codeDir}}/adr`) etc., so you should read these.
We also store organisational Architectural Decision Records as Issues in the `Autotrader/autotrader-architecture` repository in GitHub. You should search for relevant ADRs if you think it will help your review.
- Accepted ADRs will be tagged with `ADR Status: Accepted`.Prompt for fetching ADRs
Summary & Learnings
It is early days but I feel confident enough to say this is a real success story.
We have about 250(ish) deployments to production a day and 50(ish) of those have are reviewed by this process - so about 20% of all changes going out of the door. Not bad for a feature that took a couple of days to implement and is completely voluntary to use.
It isn't perfect, it will sometimes get things wrong, but then again so do humans! It doesn't replace pair programming, or human reviews, it compliments them. And as we've built the process end to end we can continue to tweak and improve it as time goes on.
We've also struggled with the bot being too nice. I know that sounds weird, but we want the content to be meaningful and actionable. There's little benefit in the bot writing things like "This is a great change, thanks."!
One final ick that I have is that we're now creating more PRs. I'm an advocate of trunk based development and generally dislike branches. This is something to keep an eye on, because it may be worse for your organisation if you end up with lots of stale PR's knocking around.
But overall I give this experiment a solid 8/10! 🤣