Istio at Scale: Sidecar
Configuring Istio using the Sidecar resource to minimise the load and footprint of both the control and data plane at scale

By default; all proxies on your mesh will receive all the config required in order to reach any other proxy. It's important to note that by "Config" - that isn't just what you put in your DestinationRule or VirtualService, but also the state of all of the Endpoints for your services too, therefore whenever you do a Deployment, or a Pod becomes unready, or your service scales, or anything else that changes state - config is pushed to all the proxies.
This behaviour is fine when you've only got a handful of services on your mesh, and it helps new users to hit the ground running with minimal friction, but as your mesh starts to grow you'll start to see:
- The control plane (
pilotoristiod) using a lot of CPU, and a surprising amount of Network IO - The memory usage of all proxies grows with the size of the mesh, as they're all storing all the config for all the services
- Pilot takes longer to push the config out to all services resulting in changes (such as new endpoints) taking longer to propagate
So what does this mean in the real world?
It's very unlikely that all of your services will need to talk to every other service. As an example, this graph shows you how our services are interconnected at Auto Trader. Almost 400 services in total, however the average amount of N+1 connections is just 5. That means in the vast majority of circumstances, the proxies would be configured with 395 sets of service configuration that they simply don't need.
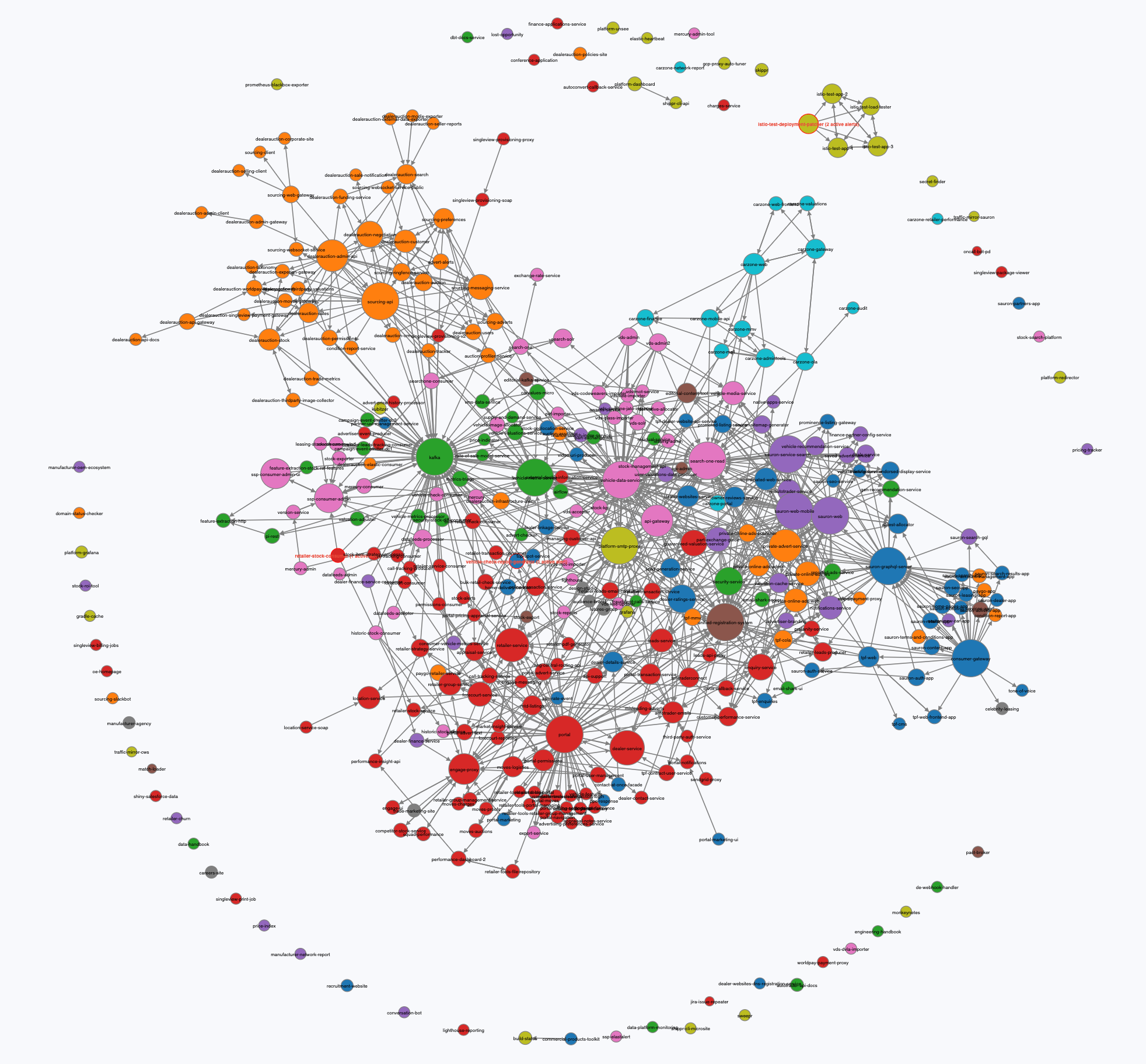
To put some numbers on this, using the example above of 400 services, performing a GET :15000/config_dump on an istio-proxy without any sidecar configuration returns a result around 5mb. Multiply that by the number of pods (1000) and you're at 5gb for a full config push to all services. That's a lot of work for the control plane to do, especially on a high-churn cluster where endpoints change frequently.
All that config impacts istio-proxy as well, drastically increasing the memory footprint. A typical proxy with just 2 or 3 services uses around 25mb of memory, however with 400 services that bumps up to 250mb. Multiply that across say 1000 proxies and you're using 240GB more RAM than you need to.
Configuring the Sidecar
To tackle this, Istio provides the Sidecar resource as a means of configuring what config the proxies should get from the control plane. Think of it as saying "Hey, Theres 400 services on this mesh, but i'm only interested in these two".
So taking an example of service-a talks to both service-b and service-c, but isn't interested in the other 397 services on the mesh, we would create a Sidecar resource that looks like this:
apiVersion: networking.istio.io/v1beta1
kind: Sidecar
metadata:
name: default
namespace: service-a
spec:
egress:
- hosts:
- "./*" # current namespace
- "istio-system/*" # istio-system services
- "service-b/*" # dependency 1
- "service-c/*" # dependency 2This example is based on each service being deployed in its own namespace.
Note 1: We don't have a workload selector here so this sidecar will apply to all proxies in the service-a namespace.
Note 2: If you apply this to an existing service, you'll need to restart your workload in order to see the memory improvement. That's because once claimed, istio-proxy doesn't release memory back to the operating system.
Monitoring Pilot
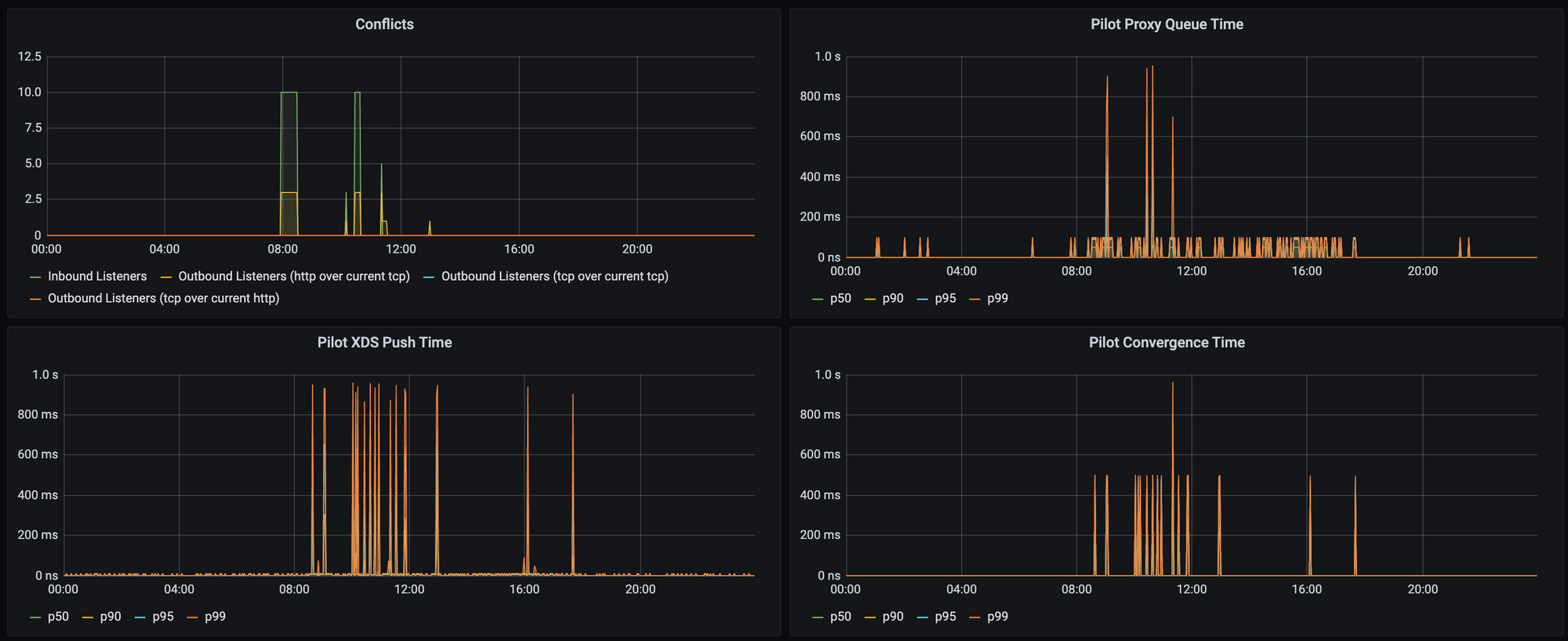
There are some important metrics to monitor in order to get an idea of how long it's taking Pilot to push configuration out, they are:
pilot_xds_push_time_bucket- Total time in seconds Pilot takes to push lds, rds, cds and eds.pilot_proxy_convergence_time_bucket- Delay in seconds between config change and a proxy receiving all required configurationpilot_proxy_queue_time_bucket- Time in seconds, a proxy is in the push queue before being dequeued
Here as you can see on our 400 service cluster, we never exceed 1 second:
Detecting Misconfiguration
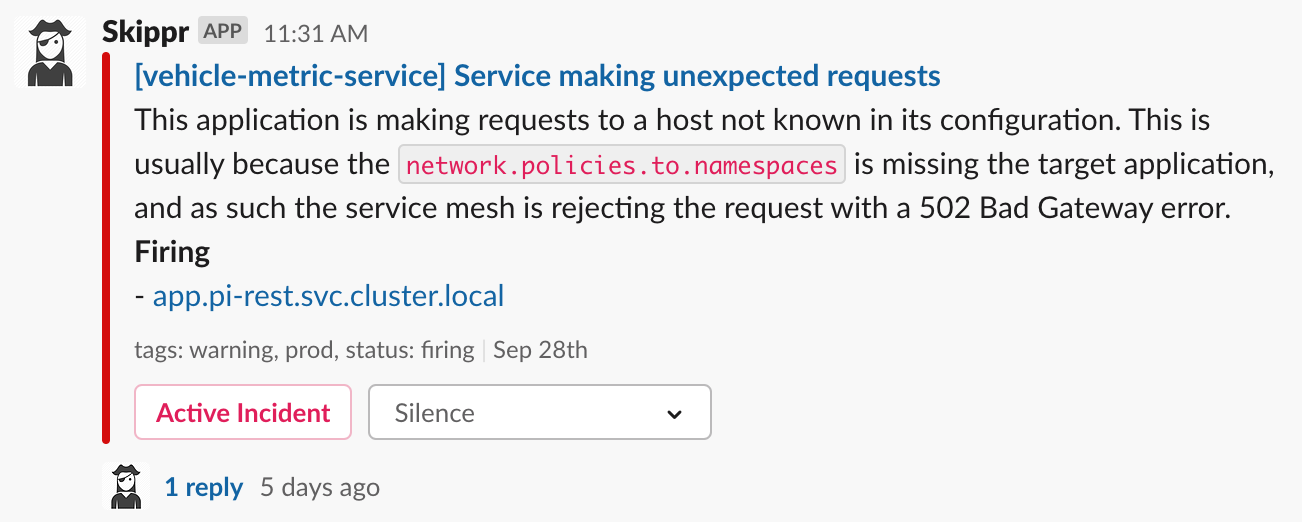
We deploy Istio configured with outboundTrafficPolicy.mode: REGISTRY_ONLY. Think of it like a default deny, which enforces our users to be specific with their configuration - if they don't add the service to their Sidecar, it isn't going to work. This currently manifests in two ways:
- The response code returned from the local proxy, when attempting to reach a service not defined in the
Sidecarwill be502. - A metric is exposed with a
response_codeof502and adestination_service_nameofBlackHoleCluster. We use that information to display a useful alert for the developer to let them know they've missed some config:
The result
On our production cluster (running some 1500 pods, 1000 with an istio-proxy), and well configured Sidecars, resource usage looks like this:
- control plane: 1GB memory, CPU never peaks more than 1vCPU
- data plane: 35GB memory, CPU between 7 and 25 vCPU depending on ops/sec
The strict configuration of the Sidecar is critical to running Istio at scale, and like anything - it's easier to do it at the start rather than going back and retrospectively adding it later.